Alibaba Unveils FunAudio-ASR with Breakthrough Noise Reduction
Alibaba's FunAudio-ASR Redefines Speech Recognition Standards
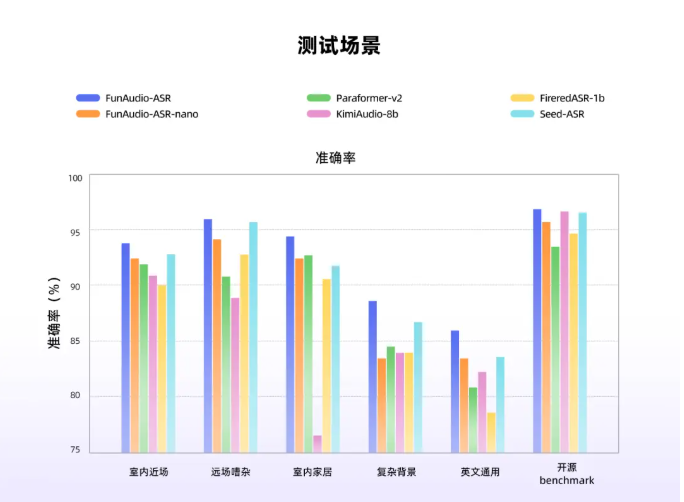
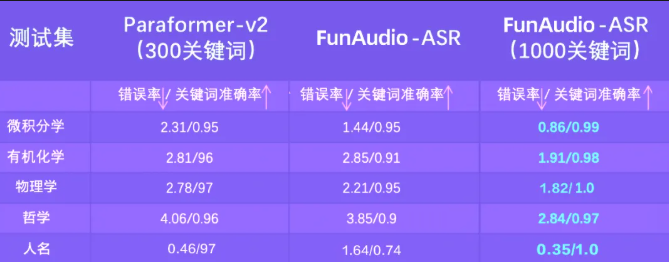
Alibaba Group's TONGYI Lab has introduced FunAudio-ASR, an end-to-end speech recognition model that dramatically improves accuracy in noisy environments through its innovative Context module. This technological advancement reduces hallucination rates from 78.5% to just 10.7% - a nearly 70% improvement that establishes new benchmarks for the industry.
Technical Breakthroughs
The model was trained on tens of millions of hours of audio data and integrates large language models' semantic understanding capabilities. Testing shows superior performance compared to competitors like Seed-ASR and KimiAudio-8B in challenging scenarios including:
- Far-field audio capture
- High-noise environments
- Multi-speaker situations
The system demonstrates particular effectiveness in business applications such as meetings and public spaces where background noise traditionally degrades recognition quality.
Deployment Options
Recognizing diverse user needs, Alibaba offers:
- Full version: Maximum accuracy for enterprise applications
- FunAudio-ASR-nano: Lightweight version maintaining core functionality while reducing computational requirements
The nano variant enables cost-effective deployment across various hardware configurations without significant performance compromises.
Current Implementations
The technology already powers several real-world applications:
- DingTalk's "AI Note-taking" feature
- Video conferencing systems
- DingTalk A1 hardware devices Developers can access the API through Alibaba Cloud's BaiLian platform, facilitating seamless integration into existing systems.
Industry Impact
The launch represents a significant leap forward for:
- Business communication tools
- Accessibility technologies
- AI-powered transcription services By dramatically improving reliability in noisy conditions, FunAudio-ASR removes a major barrier to widespread speech recognition adoption.
Key Points:
- 70% reduction in hallucination rates compared to previous solutions The Context module enables unprecedented accuracy improvements Dual deployment options accommodate different resource requirements Already implemented across Alibaba's business communication ecosystem API availability accelerates third-party adoption