Step-Audio-R1.1 Shatters Records as New Speech AI Champion
StepZen's Speech Model Outshines Tech Giants
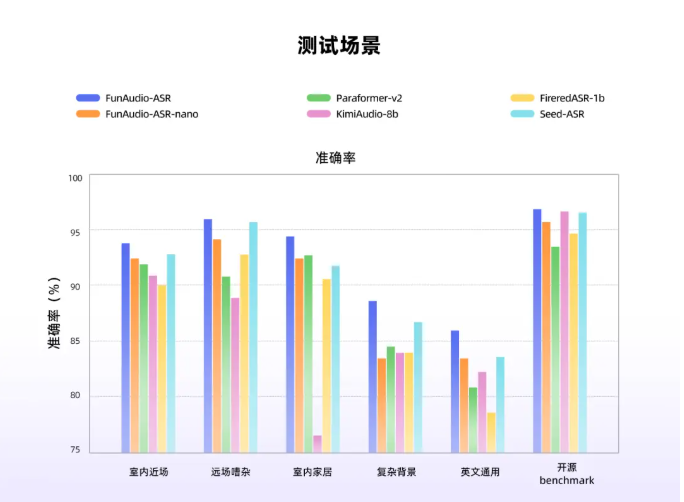
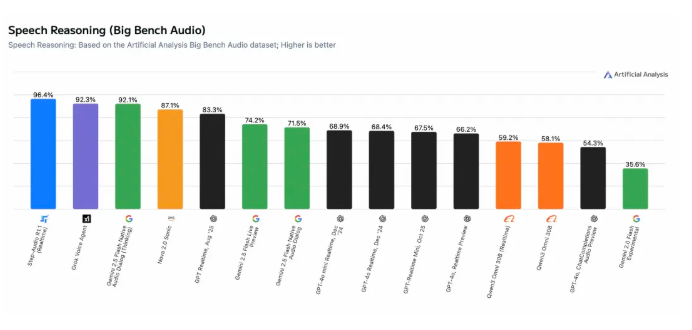
In a remarkable achievement for open-source AI, StepZen Star Company's Step-Audio-R1.1 speech reasoning model has claimed the top spot in Artificial Analysis Speech Reasoning's global evaluation rankings. The model outperformed closed-source competitors including Elon Musk's Grok, Google's Gemini, and OpenAI's GPT-Realtime with an unprecedented 96.4% accuracy rate.
What Makes This Model Special?
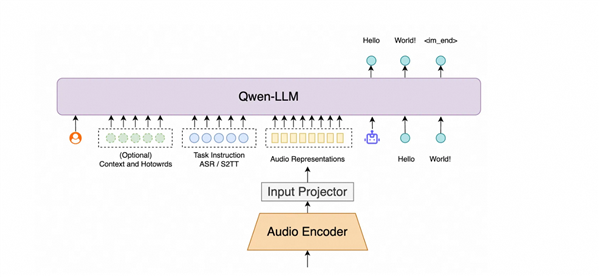
The breakthrough technology behind Step-Audio-R1.1 lies in its ability to process speech end-to-end without perceptible delay - essentially "thinking" like humans do during conversations. Unlike traditional models that analyze speech in segments, this innovation maintains context continuously while formulating responses.
"We've essentially taught the model to listen and comprehend simultaneously," explained Dr. Li Wen, StepZen's lead researcher. "When you're talking to another person, you don't wait for them to finish speaking before understanding begins - our model replicates that natural flow."
Practical Applications That Impress
At the product launch demonstration, attendees witnessed the model's capabilities firsthand:
- Accurately interpreting emotional tones in recordings of cat fights
- Providing nuanced translations of Korean pop lyrics while preserving cultural context
- Maintaining coherent dialogue across multiple simultaneous speakers
The system particularly shines in noisy environments where competing audio streams typically confuse conventional speech AIs.
Availability and Future Plans
The research team has made weights available on HuggingFace (https://huggingface.co/stepfun-ai/Step-Audio-R1.1), inviting developers worldwide to experiment with the technology. For less technical users, StepZen offers a streamlined experience through their Open Platform Experience Center.
Looking ahead, February 2027 will see the launch of complete real-time speech APIs built on this foundation. Industry analysts predict these could revolutionize sectors from customer service to language education.
Key Points:
- Record-breaking accuracy: 96.4% score surpasses all major competitors
- Human-like processing: Understands speech continuously rather than in segments
- Available now: Open-source weights on HuggingFace with demo platform access
- Coming soon: Full commercial API launch scheduled for early next year