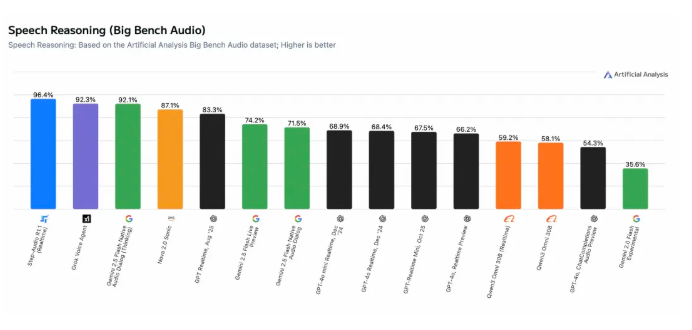
TikTok and Tsinghua Open-Source HuMo, a Multimodal Video Framework
TikTok and Tsinghua University Release Open-Source HuMo Framework
In a significant advancement for AI-powered video generation, ByteDance's intelligent creation team has partnered with Tsinghua University to open-source the HuMo framework, a multimodal system designed for Human-Centric Video Generation (HCVG). This collaboration marks a major step forward in combining academic research with industry-scale AI applications.
Technical Capabilities
The HuMo framework stands out for its ability to process three input modalities simultaneously:
- Text descriptions
- Reference images
- Audio cues
This multimodal approach allows the system to generate coherent videos where human subjects move naturally in response to complex prompts. Current implementations can produce videos at 480P and 720P resolution, with maximum lengths of 97 frames at 25 frames per second.

Innovation Highlights
The research team credits HuMo's superior performance to two key innovations:
- A carefully curated training dataset focusing on human motion patterns
- A novel progressive training methodology that outperforms traditional single-stage approaches
The framework employs an advanced data processing pipeline that maintains temporal consistency across frames while allowing precise control over character movements. Early benchmarks show HuMo achieving 15-20% better motion fidelity compared to existing single-modality solutions.
Practical Applications
Developers can leverage HuMo for various use cases including:
- Virtual content creation
- Educational video production
- AI-assisted film previsualization
The open-source release includes pre-trained models and comprehensive documentation, lowering the barrier for both academic researchers and commercial developers to experiment with the technology.
The project is available on GitHub alongside a detailed technical paper published on arXiv: https://arxiv.org/pdf/2509.08519
Key Points:
- First open-source multimodal framework specifically optimized for human video generation
- Combines text, image and audio inputs for coherent output
- Progressive training method achieves new benchmarks in motion quality
- Practical applications span entertainment, education and professional media production