Meituan LongCat Unveils UNO-Bench for Multimodal AI Evaluation
Meituan's LongCat Team Introduces Groundbreaking AI Evaluation Tool
Beijing, November 6, 2025 - Meituan's LongCat research team has unveiled UNO-Bench, a revolutionary benchmark designed to systematically evaluate multimodal large language models (MLLMs). This new tool represents a significant advancement in assessing AI systems' ability to understand and process information across different modalities.
Comprehensive Evaluation Framework
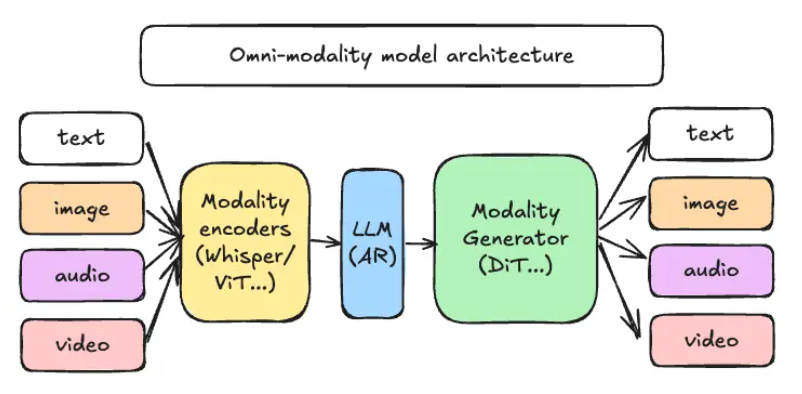
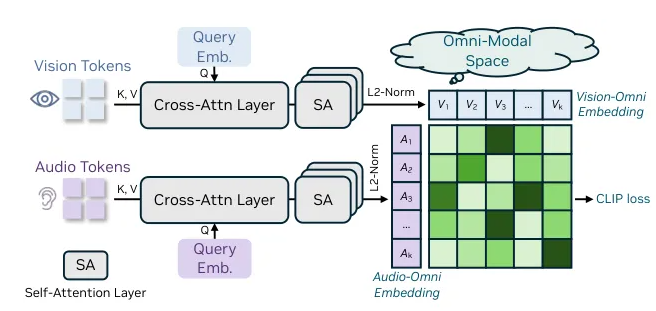
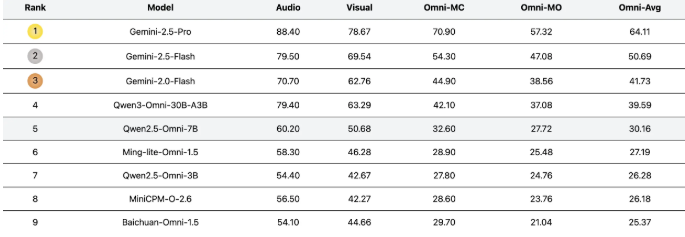
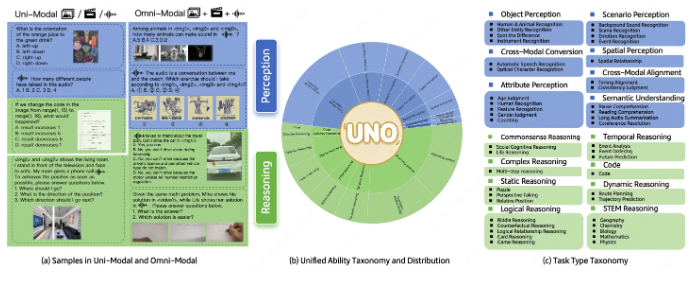
The benchmark covers 44 distinct task types and five modality combinations, providing researchers with unprecedented tools to measure model performance in both single-modal and full-modal scenarios. According to the development team, UNO-Bench was created to address the growing need for standardized evaluation metrics as multimodal AI systems become increasingly sophisticated.
Robust Dataset Design
At the core of UNO-Bench lies its meticulously curated dataset:
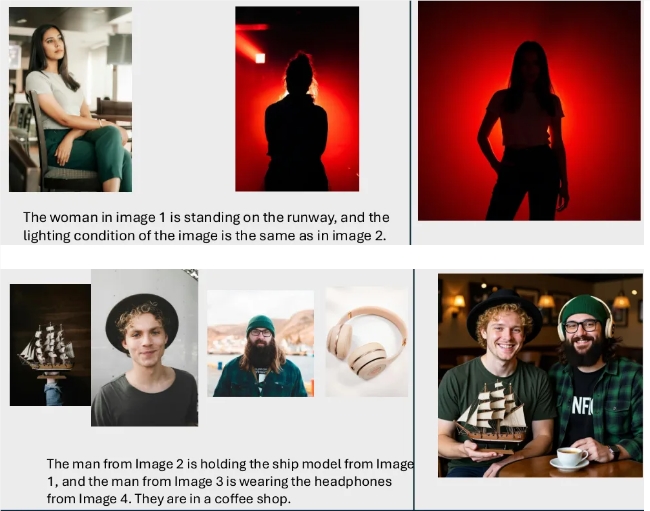
- 1,250 full-modal samples with 98% cross-modal solvability
- 2,480 enhanced single-modal samples optimized for real-world applications
- Special emphasis on Chinese-language context performance
- Automated compression processing resulting in 90% faster runtime speeds
The dataset maintains an impressive 98% consistency rate when tested against 18 public benchmarks, demonstrating its reliability for research purposes.
Innovative Evaluation Methodology
UNO-Bench introduces several groundbreaking features:
- Multi-step open-ended question format for assessing complex reasoning capabilities
- General scoring model capable of automatically evaluating six different question types
- Achieves 95% accuracy rate in automated evaluations
Future Development Plans
While currently focused on Chinese-language applications, the LongCat team is actively seeking international partners to develop:
- English-language version
- Multilingual adaptations
The complete UNO-Bench dataset is now available for download via the Hugging Face platform, with related code and documentation accessible on GitHub.
Key Points:
- UNO-Bench evaluates multimodal AI across 44 tasks and 5 modality combinations
- Features curated dataset with 98% cross-modal solvability
- Introduces innovative multi-step question format
- Currently focused on Chinese with plans for English/multilingual versions
- Available now on Hugging Face and GitHub