vLLM-Omni Bridges AI Modalities in One Powerful Framework
A Unified Approach to Multimodal AI
The AI landscape just got more interesting with the release of vLLM-Omni, an open-source framework that brings together text, image, audio, and video generation capabilities under one roof. Developed by the vLLM team, this innovative solution transforms what was once theoretical into practical code that developers can implement today.
How It Works: Breaking Down the Components
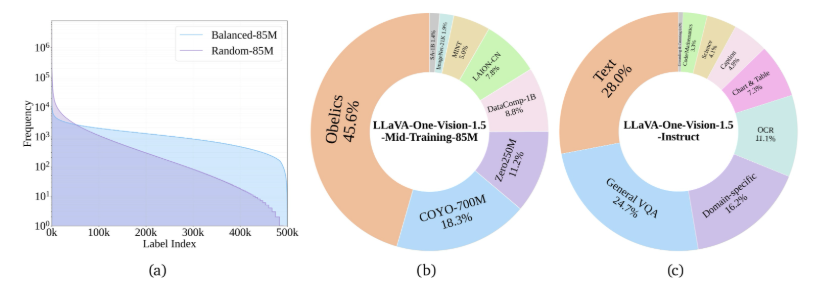
At its core, vLLM-Omni employs a decoupled pipeline architecture that divides the workload intelligently:
- Modal Encoders (like ViT and Whisper) handle the conversion of visual and speech inputs into intermediate features
- The LLM Core leverages vLLM's proven autoregressive engine for reasoning and dialogue
- Modal Generators utilize diffusion models (including DiT and Stable Diffusion) to produce final outputs
The beauty of this approach lies in its flexibility. Each component operates as an independent microservice that can be distributed across different GPUs or nodes. Need more image generation power? Scale up DiT. Experiencing a text-heavy workload? Shift resources accordingly. This elastic scaling reportedly improves GPU memory utilization by up to 40%.
Performance That Speaks Volumes
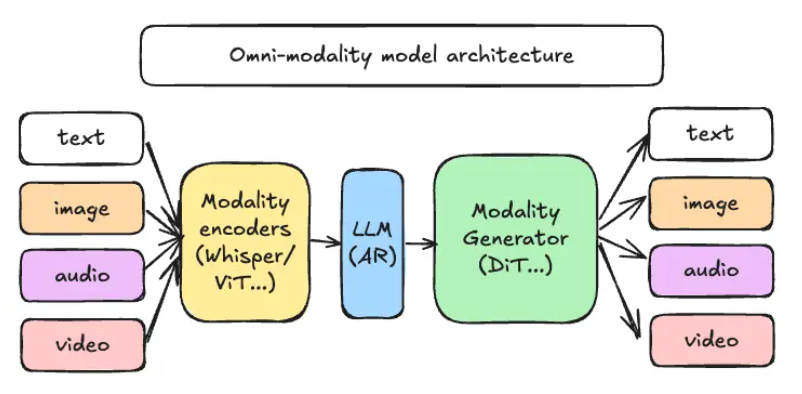
For developers worried about integration complexity, vLLM-Omni offers a surprisingly simple solution: the @omni_pipeline Python decorator. With just three lines of code, existing single-modal models can be transformed into multimodal powerhouses.
The numbers tell an impressive story. On an 8×A100 cluster running a 10 billion parameter "text + image" model:
- Throughput jumps to 2.1 times traditional serial solutions
- End-to-end latency drops by 35%
What's Next for vLLM-Omni?
The team isn't resting on their laurels. The current GitHub release includes complete examples and Docker Compose scripts supporting PyTorch 2.4+ and CUDA 12.2. Looking ahead to Q1 2026:
- Video DiT integration is planned
- Speech Codec models will be added
- Kubernetes CRD support will enable one-click private cloud deployments
The project promises to significantly lower barriers for startups wanting to build unified "text-image-video" platforms without maintaining separate inference pipelines.
Industry Reactions and Challenges Ahead
While experts praise the framework's innovative approach to unifying heterogeneous models, some caution remains about production readiness:
"Load balancing across different hardware configurations and maintaining cache consistency remain real challenges," notes one industry observer.
The framework represents an important step toward more accessible multimodal AI development - but like any pioneering technology, it will need time to mature. Project Repository
Key Points:
- First "omnimodal" framework combining text/image/audio/video generation
- Decoupled architecture enables elastic scaling across GPUs
- Simple Python decorator (@omni_pipeline) simplifies integration
- Demonstrates 2.1× throughput improvement in benchmarks
- Planned video DiT and speech Codec support coming in 2026