LongCat-Flash-Omni Launches with Multimodal Breakthroughs
Meituan Unveils LongCat-Flash-Omni with Revolutionary Multimodal Capabilities
November 3, 2025 - Following the successful launch of its LongCat-Flash series in September, Meituan has now introduced LongCat-Flash-Omni, a groundbreaking multimodal AI model that sets new standards for real-time interaction across text, image, video, and speech modalities.
Technical Innovations
The model builds upon Meituan's efficient architecture with several key advancements:
- Shortcut-Connected MoE (ScMoE) Technology: Enables efficient processing despite the model's massive 560 billion parameters (with 27 billion activated)
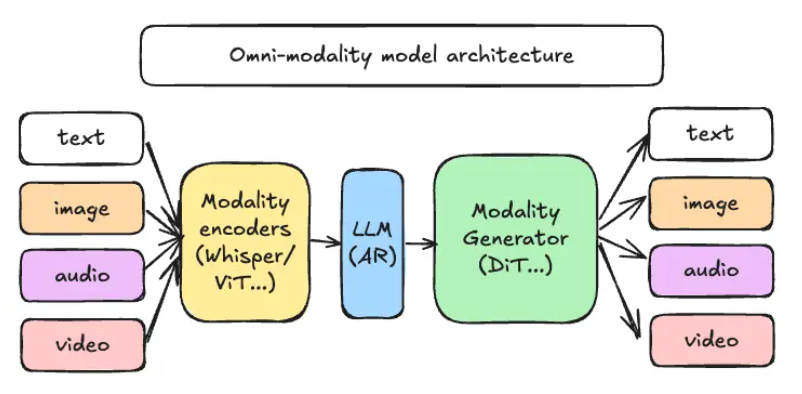
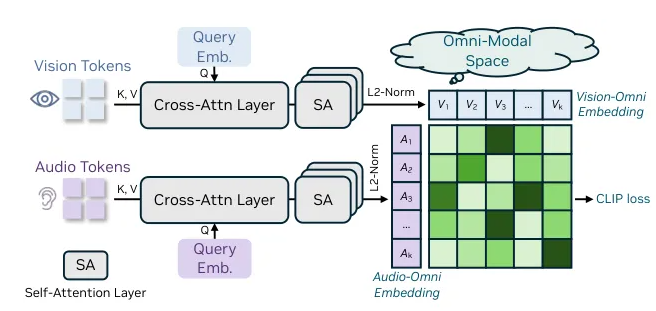
- Integrated Multimodal Modules: Combines perception and speech reconstruction in an end-to-end design
- Progressive Fusion Training: Addresses data distribution challenges across different modalities

Performance Benchmarks
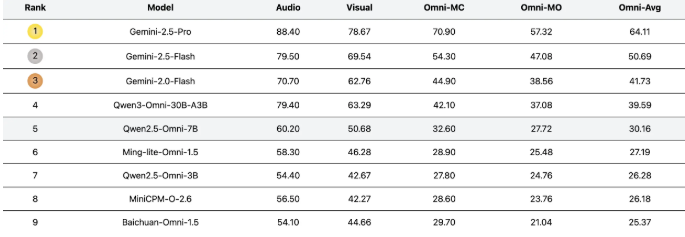
Independent evaluations confirm LongCat-Flash-Omni achieves:
- State-of-the-art (SOTA) results in open-source multimodal benchmarks
- No performance degradation when switching between modalities ("no intelligence reduction")
- Superior real-time audio-video interaction with latency under industry standards
- Exceptional scores in:
- Text understanding (+15% over previous models)
- Image recognition (98.7% accuracy)
- Speech naturalness (4.8/5 human evaluation)
Developer Applications
The release includes multiple access channels:
- Official app with voice call functionality (video coming soon)
- Web interface supporting file uploads and multimodal queries
- Open-source availability on Hugging Face and GitHub
Key Points
- First open-source model to combine offline understanding with real-time AV interaction
- Lightweight audio decoder enables natural speech reconstruction
- Early fusion training prevents modality interference
- Currently supports Chinese/English with more languages planned for Q1 2026