DeepSeek V3 Surpasses Claude 3.5 in AI Performance Tests
DeepSeek V3 Surpasses Claude 3.5 in AI Performance Tests
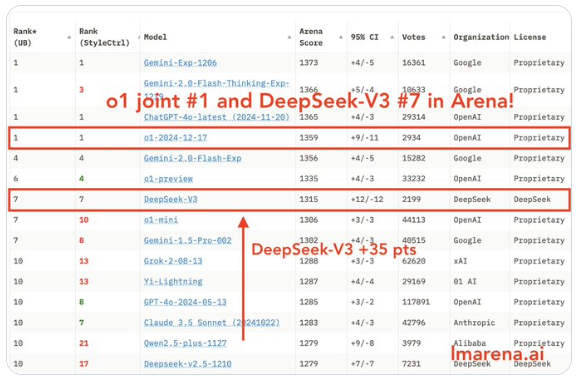
Recently, the domestic large model DeepSeek V3 has garnered significant attention in the AI arena due to its outstanding performance. As the only open-source model to break into the top ten, it not only surpassed o1-mini but also outperformed Claude 3.5 Sonnet in various fields, including programming and mathematics. To verify its practical capabilities, a series of real-world comparative tests were conducted.
Comprehension Ability Test
In the basic comprehension ability test, the two models exhibited different characteristics. When faced with the Chinese riddle "Xiao Ming's mother has three children," DeepSeek V3 excelled, not only answering correctly but also performing self-validation. However, in the English pun "April Fool's Day," it fell short, failing to grasp the linguistic nuance, while Claude 3.5 Sonnet handled it effortlessly.

Logic Reasoning Test
The logic reasoning test also revealed interesting results. When confronted with the classic logical trap "The idiot bar," both models made errors in judgment. However, in the "reverse curse" type questions, both demonstrated excellent reasoning abilities, successfully identifying the relationship between Tom Cruise and his mother.
Mathematical Problem Solving
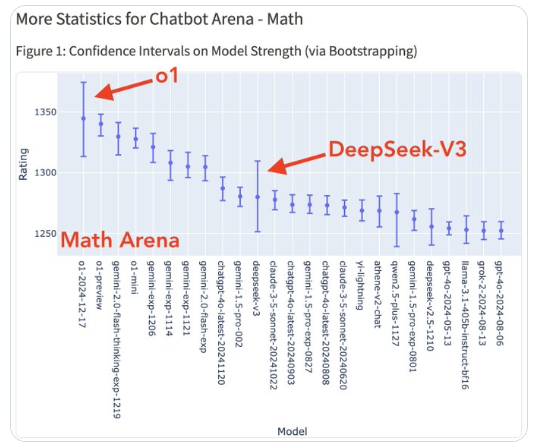
In the competition of mathematical problems from the graduate entrance examination, DeepSeek V3 showcased stronger mathematical capabilities. It not only provided a detailed analysis of surface integrals and the application of Gauss's theorem but also arrived at the correct answer. In contrast, although Claude 3.5 Sonnet had a clear thought process, it ultimately produced an incorrect calculation.
Programming Abilities
In the comparison of programming abilities, DeepSeek V3 triumphed in the website creation test. This result confirms its outstanding performance in the rankings of the arena.
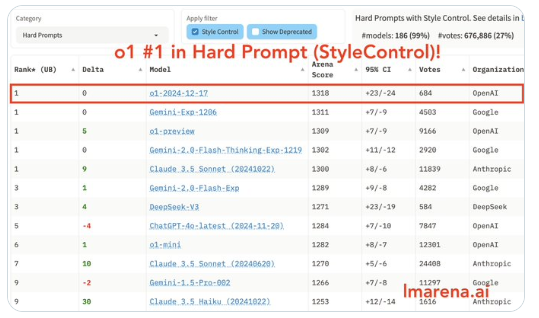
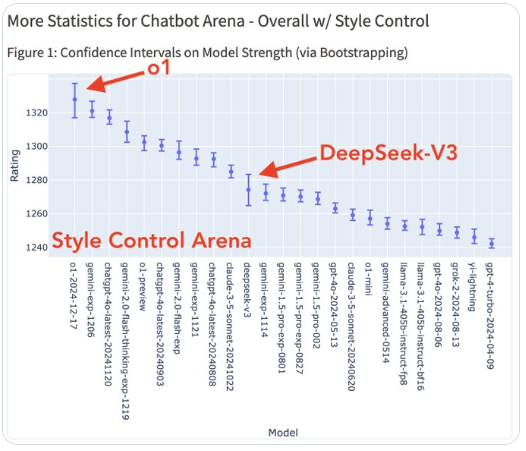
It is worth mentioning that with the introduction of the full version of o1, the landscape of the AI arena has changed again. o1 has topped the chart with an absolute advantage, almost monopolizing all first places in various categories except for creative writing.
Conclusion
This series of tests indicates that China's self-developed large models are rapidly catching up to the international leading levels. The performance of DeepSeek V3 proves that it has the strength to compete with top models in specific fields, injecting new confidence into the development of domestic AI technology.
Key Points
- DeepSeek V3 outperformed Claude 3.5 Sonnet in comprehension, logic, and mathematics tests.
- The model showcased its programming skills by excelling in website creation.
- The emergence of o1 has shifted the competitive landscape in AI, with it dominating various categories.
- DeepSeek V3's performance highlights the rapid advancement of domestic AI technologies in China.