Tongyi Qianwen Unveils Qwen3-ASR-Flash Speech Recognition Model
Tongyi Qianwen's Qwen3-ASR-Flash Sets New Standard in Speech Recognition
In a significant advancement for speech-to-text technology, Tongyi Qianwen has officially released Qwen3-ASR-Flash, its latest automatic speech recognition (ASR) model. Built upon the Qwen3 foundation model, this innovation represents a major leap forward in accuracy and functionality for voice-based AI applications.
Breakthrough Performance Metrics
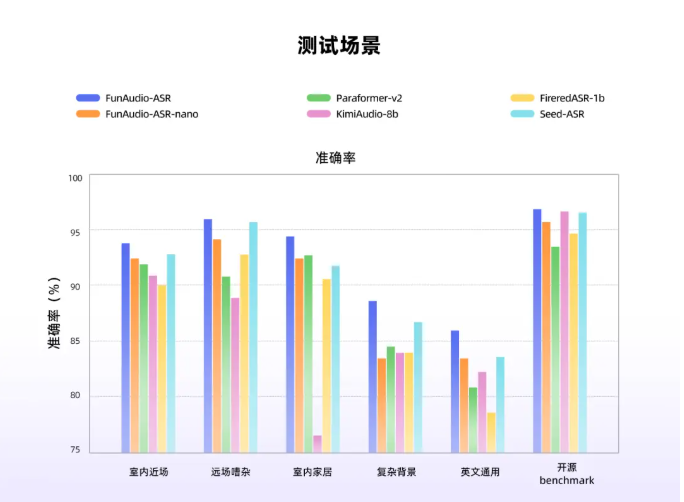
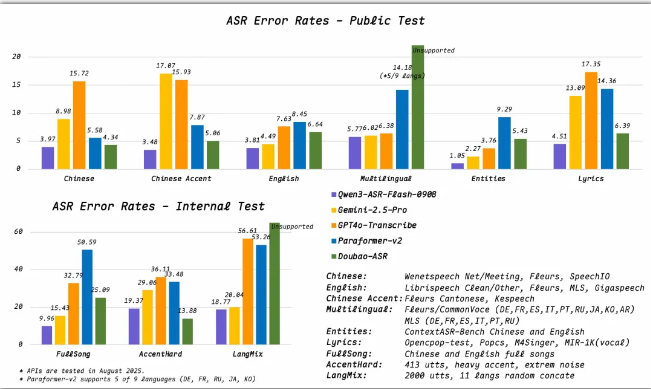
The new model demonstrates exceptional capabilities across multiple benchmarks:
- Achieves under 8% error rate in singing recognition tests
- Maintains high accuracy with long, complex sentences
- Effectively handles language switching within single utterances
- Filters background noise and non-speech segments with remarkable precision
Multilingual and Dialect Support
Qwen3-ASR-Flash stands out with its extensive language capabilities:
- Supports 11 major languages including English, Mandarin, French, German, and Japanese
- Recognizes regional variations like Sichuan dialect and Cantonese
- Accommodates different accents within language groups (e.g., British vs. American English)
The model's architecture allows it to maintain performance consistency across these diverse linguistic contexts.
Advanced Contextual Understanding
Beyond basic transcription, the model offers:
- Customizable recognition: Users can provide text context to improve entity recognition
- Named entity matching: Intelligent identification of key terms and proper nouns
- Adaptive formatting: Output adjusts based on provided contextual clues
These features make Qwen3-ASR-Flash particularly valuable for specialized domains requiring accurate terminology capture.
Technical Implementation & Availability
The model is trained on:
- Massive multimodal datasets
- Tens of millions of hours of ASR-specific data
The company has made the technology accessible through multiple platforms:
- ModelScope
- HuggingFace
- Alibaba Cloud BaiLian API
Future Development Roadmap
Tongyi Qianwen plans ongoing improvements including:
- Enhanced accuracy metrics
- Additional language support
- New feature development
- Specialized domain adaptations
The company aims to establish Qwen3-ASR-Flash as the benchmark solution for enterprise-grade speech recognition applications.
Key Points:
- Achieves industry-leading accuracy with <8% error rate in singing recognition
- Supports 11 languages including major dialects and accents
- Features customizable context adaptation for specialized use cases
- Maintains robustness in challenging acoustic environments
- Available through multiple cloud platforms for immediate implementation