Alibaba's Fun-ASR Model Boosts Speech Recognition by 15%
Alibaba's Fun-ASR Model Sets New Benchmark in Speech Recognition
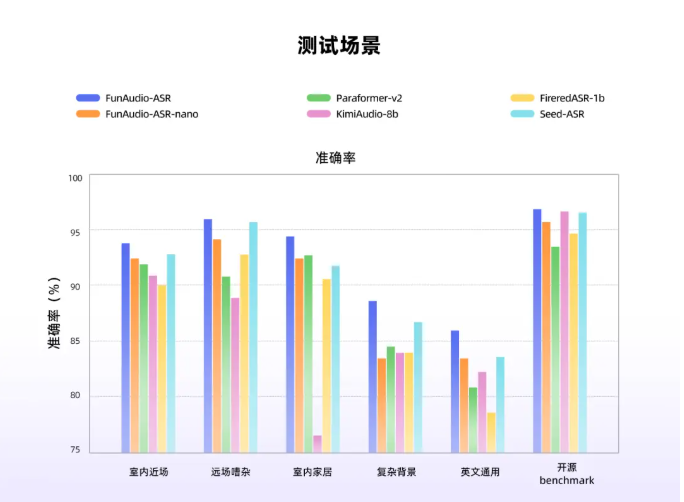
Alibaba's Tongyi has unveiled a significant upgrade to its Fun-ASR end-to-end speech recognition model, delivering over 15% accuracy improvements in specialized industry applications. The enhanced model demonstrates particular strength in vertical sectors like insurance, home decoration, and livestock, with test data showing 18% higher accuracy in insurance-related speech recognition compared to previous versions.
Technical Innovations Driving Performance
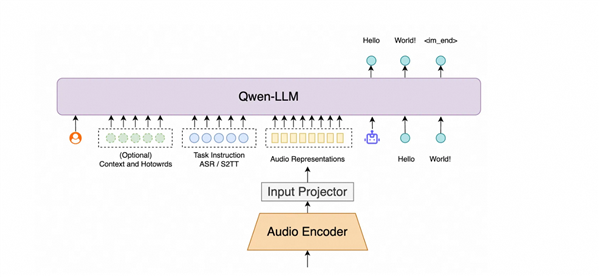
The breakthrough stems from several key technological advancements:
- Context-aware algorithms: Improved understanding of industry-specific terminology and phrases
- Qwen3 supervised fine-tuning: Enhanced model precision through advanced training techniques
- RAG retrieval enhancement: Supports import of 1,000+ custom hot words for domain-specific optimization
Addressing Industry Challenges
The development team tackled persistent speech recognition challenges through innovative solutions:
- Reinforcement learning (RL) integration: Reduces errors via dynamic optimization strategies
- Dialect recognition: Superior performance with Sichuan dialect, Cantonese, and Hokkien
- Environmental adaptability: Effective in diverse settings from meeting rooms to outdoor areas
The model's training incorporates hundreds of millions of hours of audio data and specialized terminology from over ten industries, enabling exceptional performance in niche applications. For instance, it can accurately identify animal sounds and commands in livestock environments despite background noise.
Future Applications and Impact
Alibaba's technology team emphasizes that Fun-ASR represents a shift from general-purpose to specialized speech recognition. As deployment expands across industries, its dynamic hot word updates and multimodal capabilities are expected to transform speech interaction efficiency.
Key Points
- 15-20% accuracy gains in vertical industries including insurance and home decoration
- Combines Qwen3 fine-tuning with RAG retrieval enhancement for domain-specific optimization
- Excels in challenging environments with reinforcement learning-based error reduction
- Trained on massive datasets with deep integration of industry-specific terminology
- Poised to drive innovation in professional speech interaction applications