DeepSeek V3.2-exp Cuts AI Costs with Sparse Attention Breakthrough
DeepSeek Unveils Cost-Slashing AI Model with Innovative Architecture
Artificial intelligence firm DeepSeek announced a major advancement in efficient AI processing with the release of its V3.2-exp experimental model on Monday. The breakthrough centers on a proprietary sparse attention mechanism that significantly reduces computational costs for long-context operations.

Technical Innovation: How Sparse Attention Works
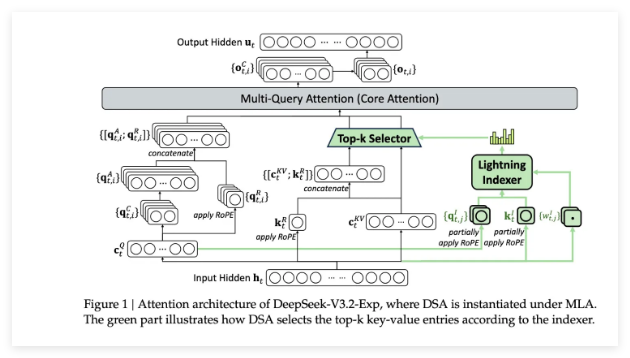
The model's architecture introduces two groundbreaking components:
- Lightning Indexer: Prioritizes critical context segments within the processing window
- Token Selection System: Precisely identifies and loads only essential tokens into the attention window
This dual-system approach maintains high accuracy while dramatically reducing server load compared to traditional transformer models.
Performance and Industry Impact
Initial benchmarks reveal compelling results:
- 50% reduction in API call costs for long-context operations
- Maintains competitive accuracy despite streamlined processing
- Open-weight availability enables immediate industry verification
The model's release includes comprehensive documentation on Hugging Face and GitHub, accompanied by a detailed academic paper explaining the technical foundations.
Strategic Significance in AI Economics
DeepSeek's innovation specifically targets inference costs - the ongoing operational expenses of running trained AI models. This differs from previous cost-reduction efforts focused primarily on training expenses (like their R1 model).
The development comes as:
- Cloud providers face mounting pressure to reduce AI service costs
- Enterprise adoption hinges on sustainable pricing models
- Long-context applications (legal, research, coding) demand efficient solutions
Key Points Summary
- Cost Reduction: Up to 50% savings demonstrated in initial tests
- Open Access: Model weights freely available for verification
- Technical Leap: Novel sparse attention architecture sets new efficiency standard
- Market Timing: Addresses critical pain point in AI service economics
- Validation Path: Industry can immediately test real-world performance