NVIDIA's Canary-Qwen-2.5B Sets New Speech Recognition Benchmark
NVIDIA Breaks Speech Recognition Barriers with Canary-Qwen-2.5B
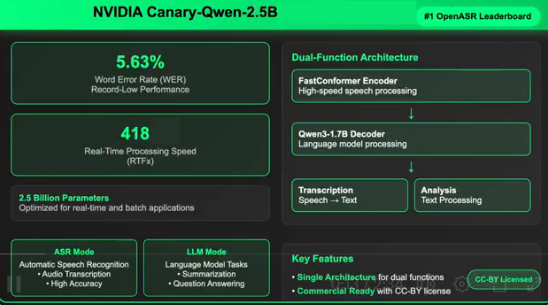
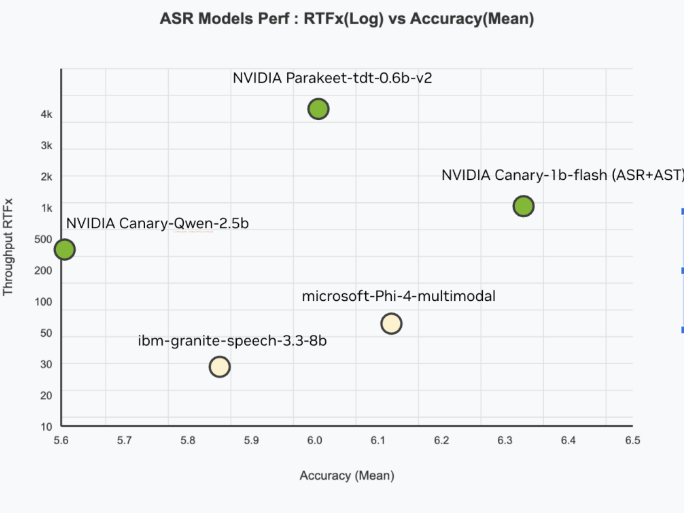
NVIDIA has unveiled Canary-Qwen-2.5B, a revolutionary hybrid model that merges automatic speech recognition (ASR) with large language model (LLM) capabilities, achieving an industry-leading 5.63% word error rate (WER). This breakthrough performance currently tops the Hugging Face OpenASR leaderboard.
Unified Architecture for Next-Gen Speech AI
The model represents a significant technical advancement by integrating transcription and language understanding into a single architecture. Unlike traditional ASR systems that require separate processing steps, Canary-Qwen-2.5B enables direct audio-to-understanding capabilities, supporting tasks like summarization and question-answering without intermediate text conversion.
Performance Highlights
Key metrics establishing Canary-Qwen-2.5B as a market leader:
- Unprecedented Accuracy: 5.63% WER outperforms all competitors
- Blazing Speed: RTFx of 418 (418x real-time processing)
- Compact Efficiency: Just 2.5B parameters despite superior performance
- Comprehensive Training: Trained on 234,000 hours of diverse English speech data
Hybrid Design Innovation
The model's architecture combines two specialized components:
- FastConformer Encoder: Optimized for high-accuracy, low-latency transcription
- Qwen3-1.7B LLM Decoder: Unmodified pre-trained language model receiving audio tokens via adapter
The modular design allows enterprises to deploy either component independently while maintaining multimodal flexibility for both speech and text inputs.
Commercial Applications Unleashed
Released under CC-BY license, the model removes barriers for enterprise adoption in:
- Professional transcription services
- Real-time meeting intelligence systems
- Regulatory-compliant document processing (legal/healthcare)
- Voice-controlled AI assistants The integrated LLM significantly improves contextual accuracy in punctuation, capitalization, and domain-specific terminology handling.
Cross-Platform Hardware Support
The solution is optimized for NVIDIA's full GPU portfolio:
- Data center: A100/H100 series
- Workstation: RTX PRO6000
- Consumer: GeForce RTX 5090 This scalability supports both cloud-based and edge deployment scenarios.
Open Innovation Approach
By open-sourcing the model architecture and training methodology, NVIDIA encourages community development of domain-specific variants. The approach pioneers LLM-centric ASR where language models become integral to the speech-to-text pipeline rather than post-processing add-ons.
The release signals a shift toward agent models capable of comprehensive understanding across multiple input modalities - positioning Canary-Qwen-2.5B as foundational infrastructure for next-generation voice-enabled applications.
Key Points:
— Achieves record 5.63% word error rate — Processes audio 418x faster than real-time — Combines ASR and LLM in unified architecture — Available under commercial-friendly CC-BY license — Supports full range of NVIDIA hardware platforms