Meituan Unveils LongCat-Flash-Chat: A 560B-Parameter AI Model
Meituan Unveils LongCat-Flash-Chat: A Breakthrough in AI Efficiency
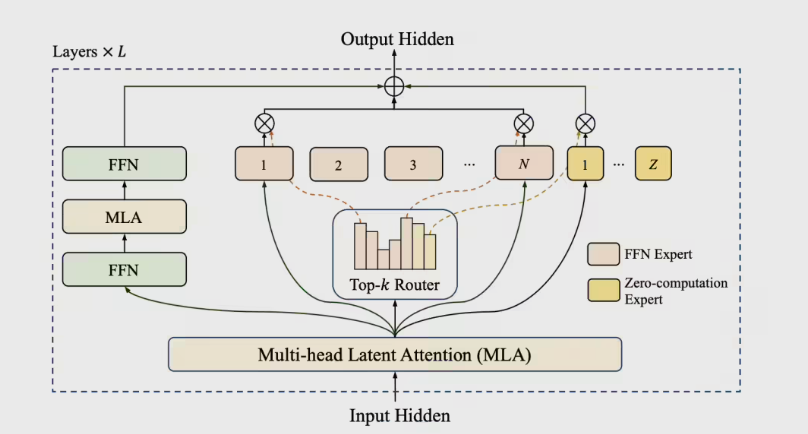
Meituan has officially released LongCat-Flash-Chat, a cutting-edge AI large model with 560 billion parameters, setting new standards in computational efficiency and performance. The model, now open-sourced, leverages an innovative Mixture of Experts (MoE) architecture, activating only 18.6B to 31.3B parameters per token through its "zero computation expert" mechanism.
Architectural Innovations
The model introduces a cross-layer channel design, significantly enhancing training and inference parallelism. On H800 hardware, LongCat-Flash achieves an impressive 100 tokens per second for single-user inference after just 30 days of training. A PID controller dynamically adjusts expert biases during training, maintaining an average of 27B activated parameters to optimize computing power usage.

Superior Agent Capabilities
LongCat-Flash stands out in agent performance, thanks to its proprietary Agentic evaluation set and multi-agent data generation strategy. It ranked first in the VitaBench benchmark for complex scenarios and outperforms larger models in tool usage tasks.
Benchmark Dominance
The model excels in general knowledge assessments:
- 86.50 on ArenaHard-V2 (2nd place overall)
- 89.71 on MMLU (language understanding)
- 90.44 on CEval (Chinese proficiency)
Open-Source Access
Meituan’s decision to open-source LongCat-Flash-Chat provides developers with unprecedented opportunities for research and application development.
Key Points:
- 560B-parameter model with MoE architecture
- 100 tokens/second inference speed
- PID-controlled training for efficiency
- Top-tier agent performance in benchmarks
- Open-sourced for community development