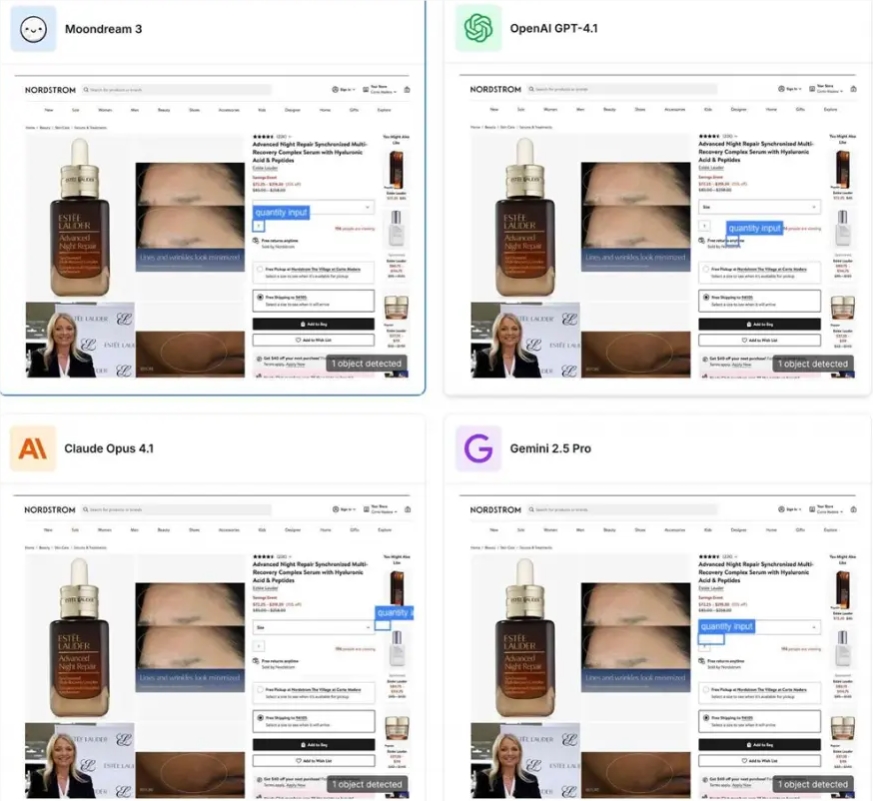
Moondream3.0 Outperforms GPT-5 in Benchmark Tests
Moondream3.0 Surpasses Leading AI Models with Efficient Design
The newly released Moondream3.0 preview version has demonstrated superior performance in benchmark tests against industry giants like GPT-5, Gemini, and Claude4. Built on an efficient Mixture of Experts (MoE) architecture, this model achieves remarkable results despite its lean parameter count.
Technical Breakthroughs
With 9 billion total parameters but activating only 2 billion during inference, Moondream3.0 delivers exceptional efficiency. Its innovative features include:
- 32K context length support for real-time workflows
- SigLIP visual encoder enabling high-resolution image processing
- Custom SuperBPE tokenizer enhancing long-context modeling
Remarkably, the model was trained on just 4.5 billion tokens—far fewer than competitors' trillion-token datasets—yet maintains competitive performance.
Multimodal Capabilities
The model shines in visual tasks:
- Open-vocabulary object detection
- Point selection and counting
- Structured JSON output generation
- UI understanding and document transcription
- Optical character recognition (OCR)
Benchmark improvements include:
| Metric | Score | Improvement |
|---|
Practical Applications
The model's versatility extends to:
- Security monitoring systems
- Drone inspection workflows
- Medical imaging analysis
- Enterprise document processing Community reports confirm successful deployments on Raspberry Pi and mobile devices. --- ### Key Points: ✅ Efficient architecture: Only activates 22% of parameters during use ✅ Open-source advantage: No heavy infrastructure required ✅ Edge-ready: Runs effectively on low-power devices