Meta's DeepConf Cuts LLM Costs Without Sacrificing Accuracy
Meta Unveils DeepConf for Efficient LLM Reasoning
Meta AI, in partnership with the University of California San Diego, has developed DeepConf (Deep Think with Confidence), an innovative approach to optimize large language model (LLM) performance. This technology addresses the critical industry challenge of balancing computational costs with reasoning accuracy in complex AI tasks.
The Confidence-Based Approach
Traditional LLM improvement strategies rely on generating multiple reasoning paths and selecting answers through majority voting. However, this brute-force method consumes significant computational resources and can propagate errors from low-quality reasoning paths.
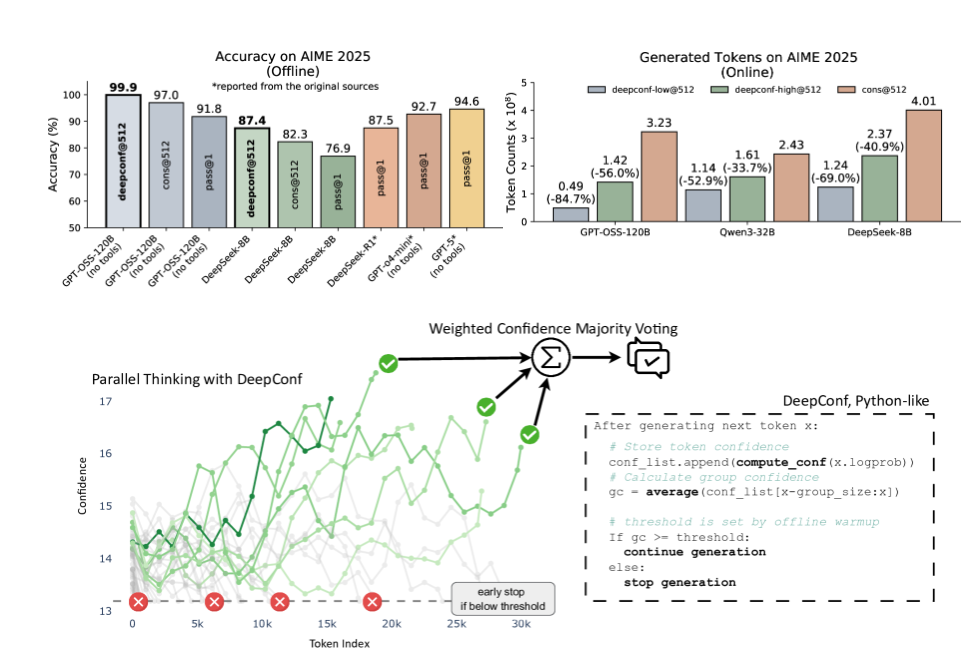
DeepConf's breakthrough lies in its dynamic evaluation of reasoning quality through multiple confidence metrics:
- Group Confidence: Average confidence across token segments
- Tail Confidence: Final-stage reasoning certainty
- Lowest Group Confidence: Identifies vulnerable reasoning points
- Bottom-10% Confidence: Focuses on least certain segments
Dual Operation Modes
The system offers two implementation strategies:
- Offline Thinking: Generates complete reasoning paths first, then selects optimal solutions through confidence-based voting
- Online Thinking: Real-time evaluation that terminates low-confidence paths early to conserve resources
Proven Performance Gains
Testing across multiple models (including DeepSeek-8B and GPT-OSS-120B) and challenging benchmarks (AIME, HMMT) demonstrated remarkable results:
- 99.9% accuracy on AIME2025 with GPT-OSS-120B (Offline Mode)
- 84.7% reduction in generated tokens versus traditional methods
- 5.8 percentage point accuracy boost for DeepSeek-8B on AIME24 (Online Mode)
- 77.9% fewer tokens consumed in online implementations
Enterprise Deployment Options
Organizations can customize DeepConf based on their operational requirements:
| Mode | Cost Reduction | Accuracy Impact | Best For |
|---|
The technology requires no model retraining and integrates seamlessly with existing inference frameworks like vLLM and TensorRT-LLM.
Key Points
- 🎯 Precision Optimization: Replaces uniform voting with confidence-weighted path selection
- ⚡ Resource Efficiency: Achieves near-perfect accuracy while reducing token generation by 84.7%
- 🛠️ Flexible Implementation: Choose between conservative (high accuracy) or aggressive (high efficiency) modes
- 🔌 Plug-and-Play: Compatible with major inference frameworks without model modifications