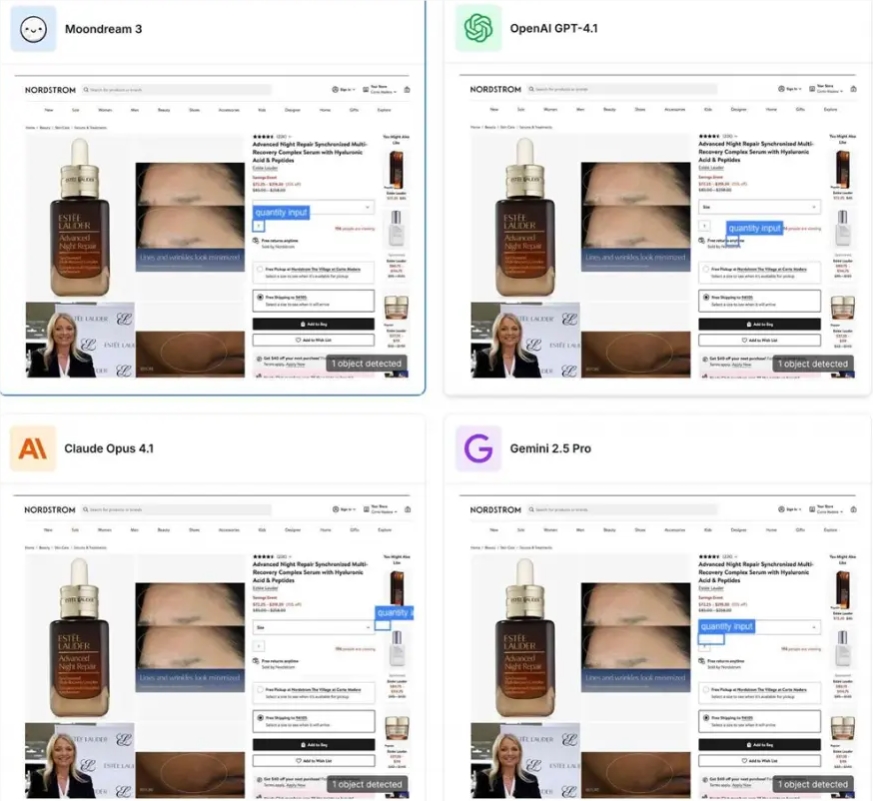
Moondream 3.0 Outperforms GPT-5 and Claude 4 with Lean Architecture
Moondream 3.0: A Lightweight VLM Challenging Industry Leaders
A new contender has emerged in the Vision Language Model (VLM) space, demonstrating that size isn't everything when it comes to AI performance. Moondream 3.0, with its innovative architecture, has achieved benchmark results surpassing those of much larger models like GPT-5 and Claude 4.
Technical Breakthroughs Driving Performance
The model's success stems from its efficient Mixture of Experts (MoE) architecture featuring:
- Total parameters: 9B
- Activated parameters: Only 2B during inference
- SigLIP visual encoder supporting multi-cropping channel stitching
- Custom SuperBPE tokenizer
- Multi-head attention mechanism with advanced temperature scaling
This design maintains the computational efficiency of smaller models while delivering capabilities typically associated with much larger systems. Remarkably, Moondream 3.0 was trained on just 450B tokens, significantly less than the trillion-token datasets used by its competitors.
Expanded Capabilities Across Domains
The latest version shows dramatic improvements over its predecessor:
Benchmark Improvements:
- COCO object detection: +20.7% to 51.2
- OCRBench score: Increased from 58.3 to 61.2
- ScreenSpot UI F1@0.5: Reached 60.3
The model now supports:
- 32K context length for real-time interactions
- Structured JSON output generation
Complex visual reasoning tasks including:
- Open-vocabulary object detection
- Point selection and counting
- Advanced OCR capabilities
Practical Applications and Deployment
The model's efficiency makes it particularly suitable for:
- Edge computing scenarios (robotics, mobile devices)
- Real-time applications requiring low latency
- Cost-sensitive deployments where large GPU clusters aren't feasible
The development team emphasizes Moondream's "no training, no ground-truth data" approach that allows developers to implement visual understanding capabilities with minimal setup.
Key Points:
- Moondream achieves superior performance despite having fewer activated parameters than competitors. 2.The SigLIP visual encoder enables efficient high-resolution image processing. 3.Structured output generation opens new possibilities for application integration. 4.Current hardware requirements are modest (24GB GPU), with optimizations coming soon.