OpenAudio Launches S1-Mini: A Lightweight, Open-Source TTS Model
The AI voice technology landscape has gained a powerful new tool with the release of OpenAudio S1-Mini, an open-source text-to-speech (TTS) model developed by Fish Audio. This lightweight version of the acclaimed S1 model brings professional-grade voice synthesis capabilities to resource-constrained environments while maintaining impressive performance.
Technical Breakthrough in a Compact Package
Distilled from its 4B-parameter predecessor, S1-Mini operates with just 0.5 billion parameters—a remarkable reduction that makes it suitable for edge devices and local applications. Despite its smaller size, the model doesn't compromise on quality. Trained on over 2 million hours of audio data, it supports 14 languages including Chinese, English, Japanese, and French.
What sets S1-Mini apart is its emotional range. The model generates more than 50 types of vocal expressions, from anger and happiness to laughter and crying sounds. These capabilities produce remarkably human-like speech that could easily be mistaken for real recordings.
Democratizing Voice Technology
The decision to open-source S1-Mini represents a strategic move to lower barriers in AI voice development. Available for free download on Hugging Face (with non-commercial use terms), the model provides small teams and independent developers access to technology that previously required expensive subscriptions.
OpenAudio has also launched an online demo platform, allowing potential users to experience the model's capabilities firsthand. This transparency builds community trust while encouraging collaborative improvement of the technology.
Competitive Performance Metrics
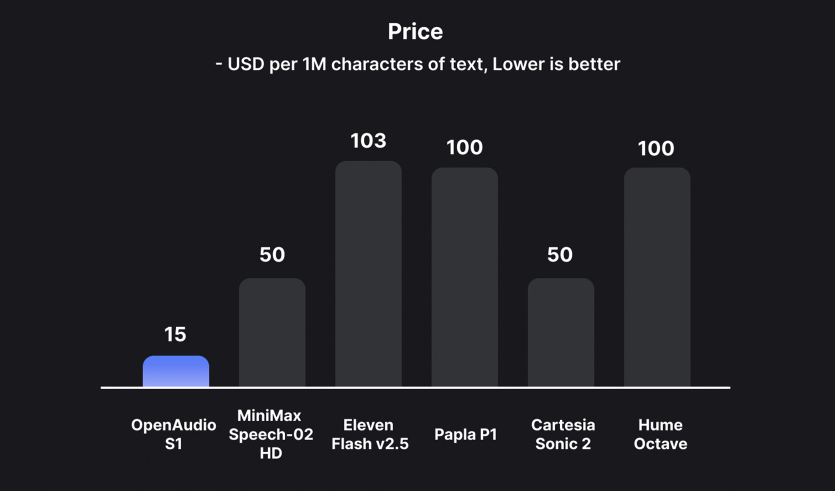
Independent testing on platforms like Hugging Face's TTS Arena reveals that S1-Mini holds its own against commercial offerings from ElevenLabs and OpenAI. The model's secret weapon is its use of Reinforcement Learning with Human Feedback (RLHF), which fine-tunes outputs for natural flow and emotional authenticity.
While currently restricted to non-commercial use, S1-Mini offers tremendous value for academic research and personal projects—particularly in multilingual applications where its performance shines.
Versatile Applications Across Industries
The education sector could leverage S1-Mini for language learning tools, while media producers might use it for audiobook narration or podcast generation. Interactive applications stand to benefit from its special effects capabilities like laughter or shouting—features that add depth to virtual characters.
Global adoption appears promising thanks to robust non-English language support. This positions S1-Mini as a potential game-changer in markets underserved by existing TTS solutions.
Future Developments
Fish Audio plans continuous improvements to S1-Mini, including expanded language support and potential real-time application versions. As the open-source community contributes to its development, the model could challenge commercial TTS monopolies and drive innovation across the industry.
The project is available at: https://huggingface.co/fishaudio/openaudio-s1-mini
Key Points
- OpenAudio S1-Mini offers high-quality TTS with just 0.5B parameters
- Supports 14 languages and over 50 emotional vocal expressions
- Available as free open-source software on Hugging Face (non-commercial)
- Outperforms some commercial models in naturalness tests
- Potential applications span education, entertainment, and interactive media