Alibaba's Qwen3-VL Model Boosts Visual AI Capabilities
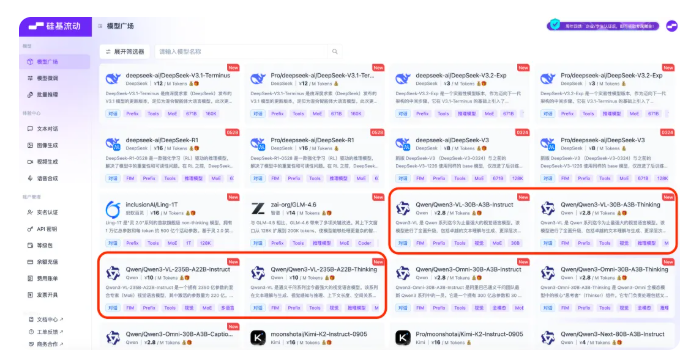
Alibaba's Qwen3-VL Model Launches on Silicon Flow Platform
The Silicon Flow platform has integrated Alibaba's latest open-source Qwen3-VL series models, marking a significant advancement in visual understanding, temporal analysis, and multimodal reasoning. This release addresses critical challenges in processing blurry images, complex videos, and fleeting moments through enhanced visual cognition technology.
Enhanced Visual Processing Capabilities
The Qwen3-VL series demonstrates exceptional image recognition performance, supporting OCR in 32 languages with accuracy maintained under low-light, blurred, or tilted conditions. Its dual competency in text and image comprehension rivals pure language models, enabling seamless multimodal integration.
Breakthrough Video Analysis Features
For video content, the model natively handles:
- 256K context processing (expandable to 1M)
- Hour-long video analysis
- Second-by-second indexing
- Precise timestamp alignment
These capabilities allow efficient location of key events within extended footage.

Intelligent Interface Interaction
The model exhibits advanced behavioral intelligence including:
- Direct PC/mobile interface interaction
- UI element recognition
- Tool invocation functionality
- Visual programming outputs (Draw.io charts, HTML/CSS/JS) It particularly excels in STEM applications and mathematical reasoning tasks.
Technical Innovations
The Qwen3-VL achieves superior performance through:
- Interleaved multi-dimensional rotary position encoding
- Deep stacking fusion technology These innovations enhance long-video reasoning and image feature capture.
The model outperforms closed-source alternatives in multiple visual perception benchmarks while demonstrating strong generalization capabilities.
The Silicon Flow platform offers developers comprehensive large-model services spanning language, image, and audio processing. New users can access trial credits to evaluate the model's capabilities.
Key Points:
🌟 Multilingual OCR: Supports 32 languages with robust image processing 🎥 Extended Video Analysis: Processes hours-long content with frame-accurate indexing 🖥️ Interface Intelligence: Direct device interaction for task automation