DeepSeek's New OCR Tech Mimics Human Vision, Slashes Costs
DeepSeek's Visionary Leap: OCR That Sees Like Humans
Imagine an AI that doesn't just scan documents mechanically, but actually reads them like you do - focusing on what matters, skipping the unimportant bits. That's exactly what DeepSeek has achieved with its newly released OCR2 visual encoder.
The Chinese AI company's breakthrough technology mimics how human vision works. "When we read," explains the research team, "our eyes don't move in perfect lines like a scanner. They jump between important words and phrases." Traditional computer vision systems waste resources processing every pixel equally - OCR2 changes that completely.
Smarter Scanning, Faster Processing
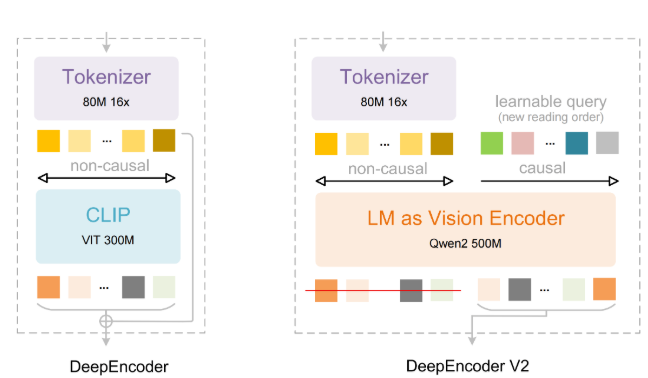
At the heart of this innovation lies a radical architectural shift. DeepSeek abandoned conventional CLIP components in favor of a lightweight language model approach using "causal flow tokens." These tokens allow the system to reorganize visual information contextually - just like your brain prioritizes meaningful content over blank spaces when reading.
The efficiency gains are staggering. Where competitors might chew through 6,000 tokens processing an image, OCR2 gets by with just 256-1,120 tokens - an 80% reduction that translates to faster performance and lower costs. For businesses drowning in paperwork or developers building document-heavy apps, these savings could be game-changing.
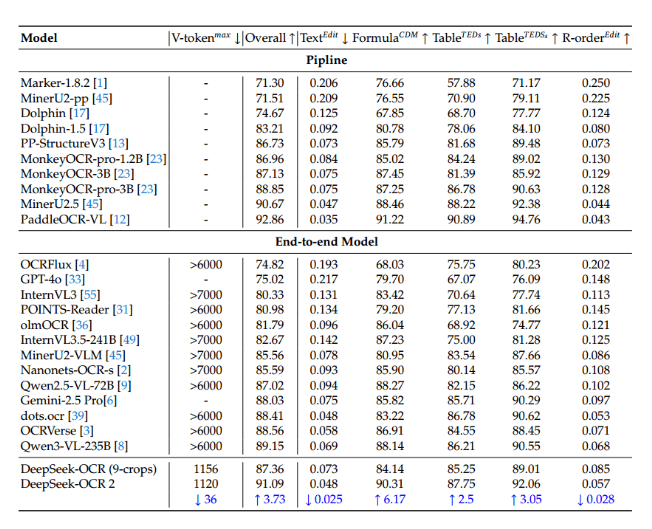
Benchmark Dominance
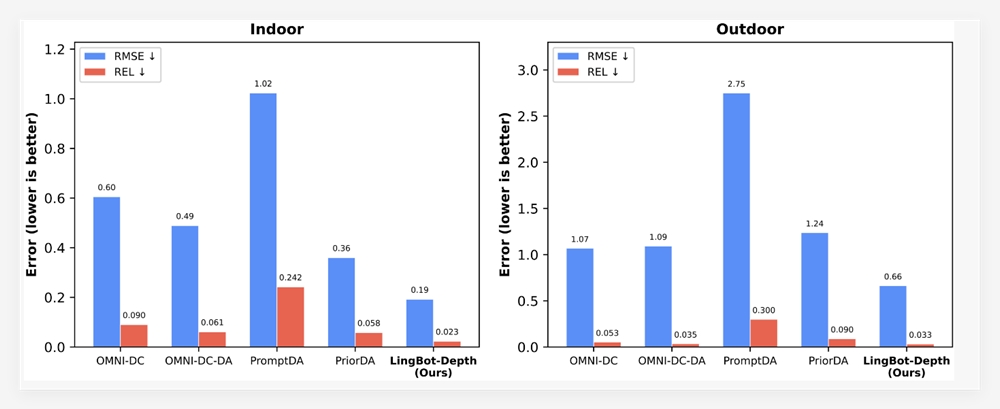
The numbers speak volumes. In rigorous OmniDocBench testing - considered the gold standard for document AI - OCR2 scored an impressive 91.09%, surpassing Google's Gemini3Pro across multiple metrics. Its ability to understand reading order and extract meaning rather than just text gives it particular strength with complex layouts like forms or multi-column documents.
What makes this release especially exciting is DeepSeek's decision to open-source both the code and model weights. This transparency invites collaboration and could accelerate progress toward truly unified multimodal AI systems - where text, voice and images flow seamlessly together within a single framework.
Key Points:
- Human-like efficiency: Processes documents with 80% fewer tokens than competitors by mimicking natural eye movement patterns
- Benchmark-beating performance: Outscored Gemini3Pro (91.09% vs undisclosed) in comprehensive document understanding tests
- Open innovation: Publicly available architecture could spark new breakthroughs in multimodal AI integration