Alibaba's New AI Voice Model Brings Hollywood-Quality Dubbing Within Reach
Alibaba Breaks New Ground in AI Voice Technology
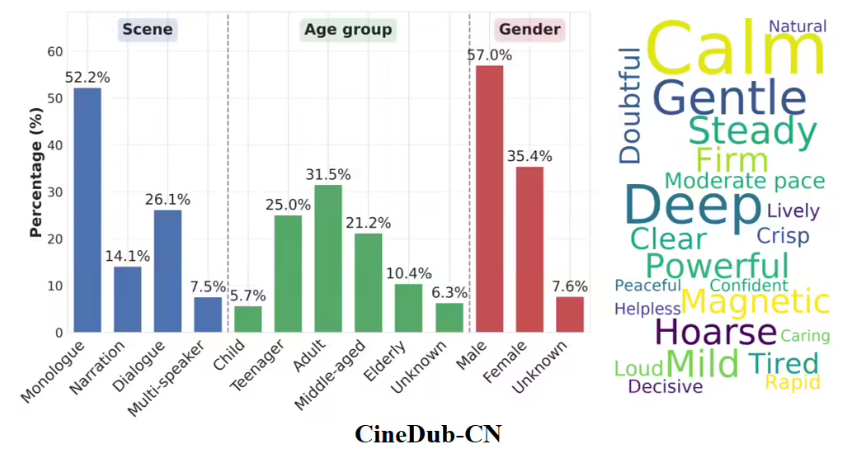
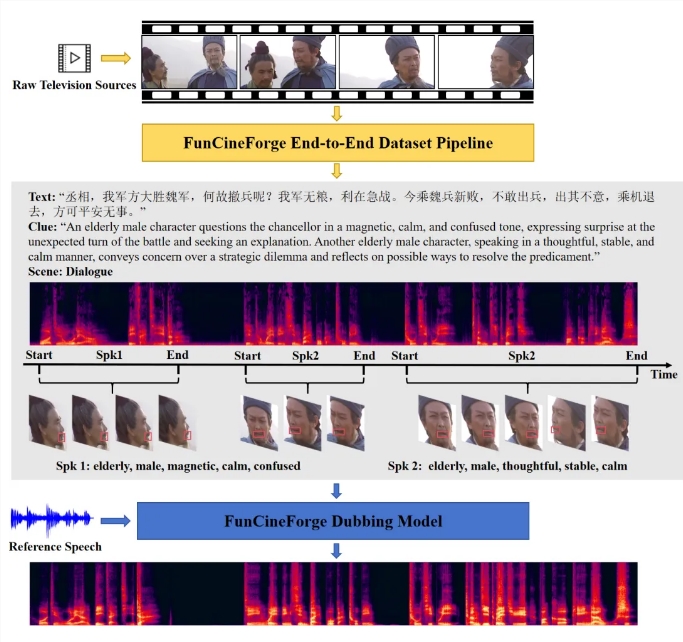
Imagine watching a foreign film where the dubbed voices perfectly match the actors' lips and emotions - no more awkward mismatches that pull you out of the story. That future just got closer with Alibaba Tongyi Lab's release of Fun-CineForge, an open-source voice synthesis model that achieves what many thought impossible: true film-quality dubbing through artificial intelligence.
Solving Hollywood's Toughest Problems
The breakthrough comes from tackling three persistent pain points simultaneously:
- Lip-sync precision that holds up under challenging filming conditions
- Emotional authenticity missing from most synthetic voices
- Character consistency when handling multiple speakers
"Traditional models focus on either text or visuals," explains Dr. Li Wen, lead researcher on the project. "We introduced 'time modality' - essentially teaching the AI to understand exactly when each syllable should occur relative to visual cues."
This temporal awareness allows Fun-CineForge to maintain synchronization even when actors turn away from camera or scenes cut rapidly between shots. Early tests show it handles blocked faces and motion blur with surprising accuracy.
Behind the Scenes: The CineDub Advantage
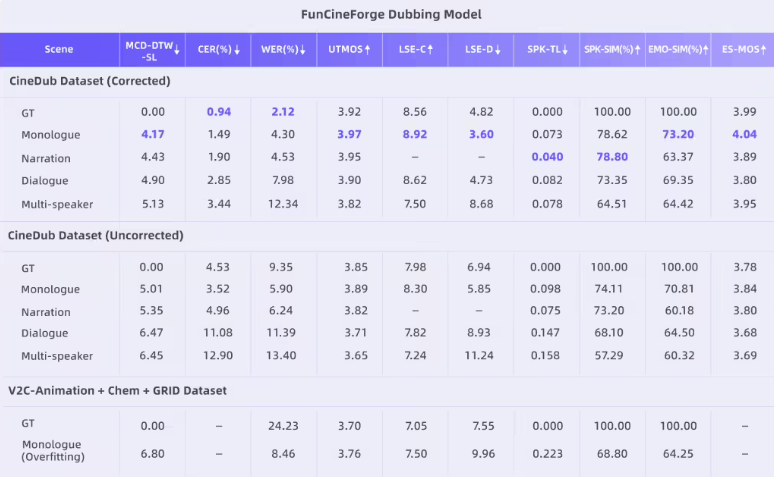
The team didn't stop at the model itself. They revolutionized training data preparation with their CineDub dataset construction method. Using large language models to automate transcription and annotation, they've reduced:
- Word error rates to ~1% (industry standard hovers around 5-7%)
- Speaker separation errors to just 1.20%
"What used to take weeks of manual work now happens automatically," notes Chen Ying, project manager. "We're essentially giving filmmakers professional-grade tools at open-source prices."
Where You Can Try It Today
The model debuted March 16 across three major platforms:
Current capabilities include processing 30-second video clips with support for monologues, duets, and multi-character dialogues - a first for open-source models of this caliber.
What This Means for Creators
The implications stretch far beyond technical achievement:
- Independent filmmakers can now achieve dubbing quality rivaling major studios
- Animation studios may slash post-production timelines by weeks
- Language localization becomes dramatically more accessible globally
- Educational content creators gain professional narration tools
- Game developers can implement dynamic voice acting more affordably
The technology still has limitations - longer sequences require chaining multiple clips together - but represents a quantum leap toward making cinematic-quality audio production available to all.