Ant Group's Latest AI Model Breaks New Ground in Multimodal Tech
Ant Group Takes Multimodal AI to New Heights with Open-Source Release
In a move that could reshape the AI development landscape, Ant Group has made its advanced Ming-Flash-Omni 2.0 model freely available to developers worldwide. This isn't just another incremental update - it represents significant leaps in how machines understand and create across multiple media formats.
Seeing, Hearing, and Creating Like Never Before
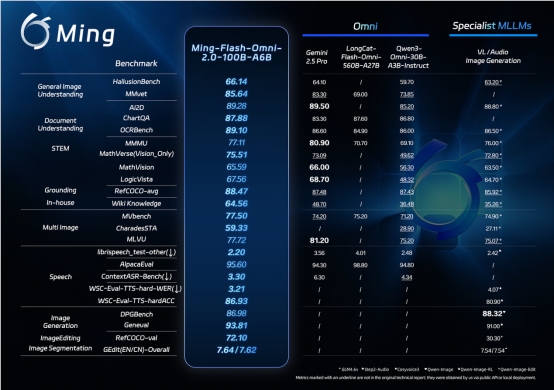
The numbers tell an impressive story: benchmark tests show Ming-Flash-Omni 2.0 surpassing even Google's Gemini 2.5 Pro in key areas of visual language processing and audio generation. But what really sets this model apart is its ability to handle three audio elements - speech, sound effects, and music - simultaneously on a single track.
Imagine describing "a rainy Paris street with soft jazz playing as a woman speaks French" and getting perfectly synchronized output. That's the level of control developers now have access to, complete with adjustments for everything from emotional tone to regional accents.
From Specialized Tools to Unified Powerhouse
Zhou Jun, who leads Ant Group's Bai Ling model team, explains their philosophy: "We're moving beyond the old trade-off between specialization and generalization. With Ming-Flash-Omni 2.0, you get both - deep capability in specific areas combined with flexible multimodal integration."
The secret lies in the Ling-2.0 architecture underpinning this release. Through massive datasets (we're talking billions of fine-grained examples) and optimized training approaches, the team has achieved:
- Visual precision that can distinguish between nearly identical animal species or capture intricate craft details
- Audio versatility supporting real-time generation of minute-long clips at just 3.1Hz frame rates
- Image editing stability that maintains realism even when altering lighting or swapping backgrounds
What This Means for Developers
The open-source release transforms these capabilities into building blocks anyone can use. Instead of stitching together separate models for vision, speech, and generation tasks, developers now have a unified starting point that significantly reduces integration headaches.
"We see this as lowering barriers," Zhou notes. "Teams that might have struggled with complex multimodal projects before can now focus on creating innovative applications rather than foundational work."
The model weights and inference code are already live on Hugging Face and other platforms, with additional access through Ant's Ling Studio.
Looking Ahead
While celebrating these achievements, Ant's researchers aren't resting. Next priorities include enhancing video understanding capabilities and pushing boundaries in real-time long-form audio generation - areas that could unlock even more transformative applications.
The message is clear: multimodal AI is evolving rapidly from specialized tools toward integrated systems that better mirror human perception and creativity.
Key Points:
- Open-source availability: Ming-Flash-Omni 2.0 now accessible to all developers
- Performance benchmarks: Outperforms leading models in visual/audio tasks
- Unified architecture: Single framework handles multiple media types seamlessly
- Practical benefits: Reduces development complexity for multimodal projects
- Future focus: Video understanding and extended audio generation coming next



