Tongyi's Breakthrough: AI Voice Acting Gets Emotional
Tongyi Lab Unveils Game-Changing AI Voice Model
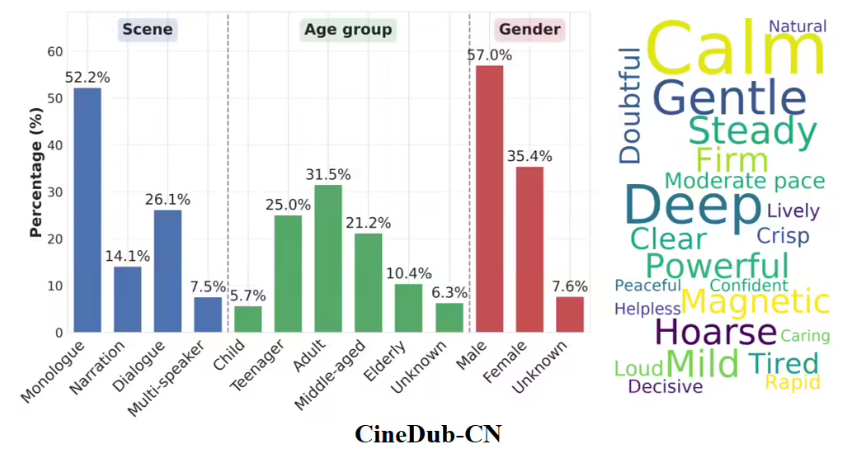
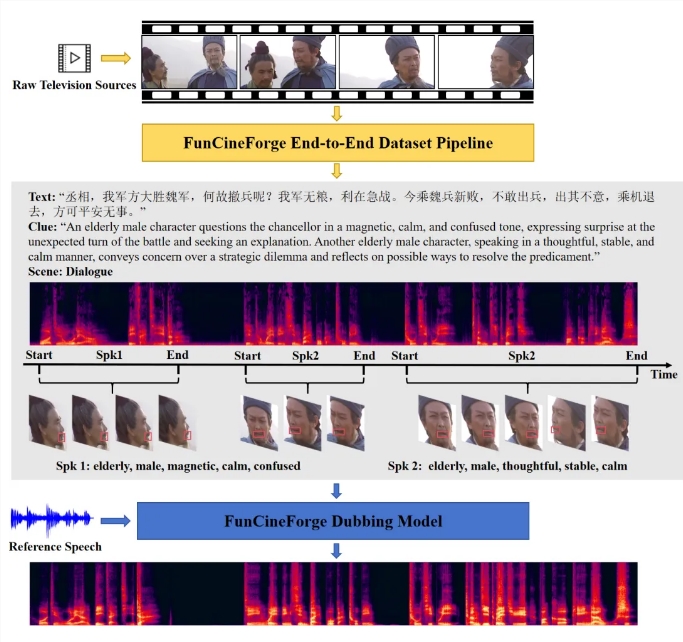
Remember when AI voices sounded like monotone robots reading a grocery list? Those days may be ending thanks to Tongyi Lab's latest innovation. On March 16, the Alibaba research division open-sourced Fun-CineForge, the world's first multimodal model capable of film-quality voice acting.
Breaking Through the Last Human Stronghold
While AI has conquered text and image generation, authentic voice acting remained stubbornly human - until now. "Film dialogue isn't just about words," explains Dr. Lin Wei, Tongyi's lead researcher. "It's about catching that hitch in breath during an emotional scene or matching lip movements perfectly."
The new model tackles these challenges head-on with:
- Context-aware emotional modulation
- Spatial audio processing for realistic environments
- Precise lip-sync capabilities
- Multi-language support
More Than Just Code
What sets Fun-CineForge apart is its holistic approach. Alongside the model architecture, Tongyi provides guidelines for building high-quality training datasets. "We're not just giving creators a tool," says Dr. Lin, "we're teaching them how to make their own."
The implications are staggering:
- Indie filmmakers can achieve Hollywood-quality dubbing
- International productions get accurate localization
- Animation studios reduce costly recording sessions
- Gaming developers create dynamic NPC dialogue
The Future Sounds Human
With this release following closely behind Qwen3-Omni, Tongyi appears determined to dominate multimodal AI. As these technologies mature, they could reshape entire industries - imagine binge-watching foreign shows with perfectly synced emotional performances instead of stiff subtitles.
The model is already available on major open-source platforms. One thing's certain: your next favorite show might feature voices that never stood in a recording booth.
Key Points:
- Film-grade quality: Captures subtle emotional nuances previously exclusive to human actors
- Open-source advantage: Makes professional tools accessible beyond major studios
- Multimodal future: Represents another step toward comprehensive AI media creation