Microsoft's Tiny Powerhouse: Half-Billion Parameter AI Speaks Almost Instantly
Microsoft Breaks Speed Barrier With Compact Speech AI
In a breakthrough for real-time voice technology, Microsoft's new VibeVoice-Realtime-0.5B proves bigger isn't always better. This lean, half-billion parameter model generates speech so quickly - starting responses in roughly 300 milliseconds - that it creates what developers call "the anticipation effect." Listeners begin hearing replies before they've mentally completed their own sentences.
Natural Speech at Lightning Speed
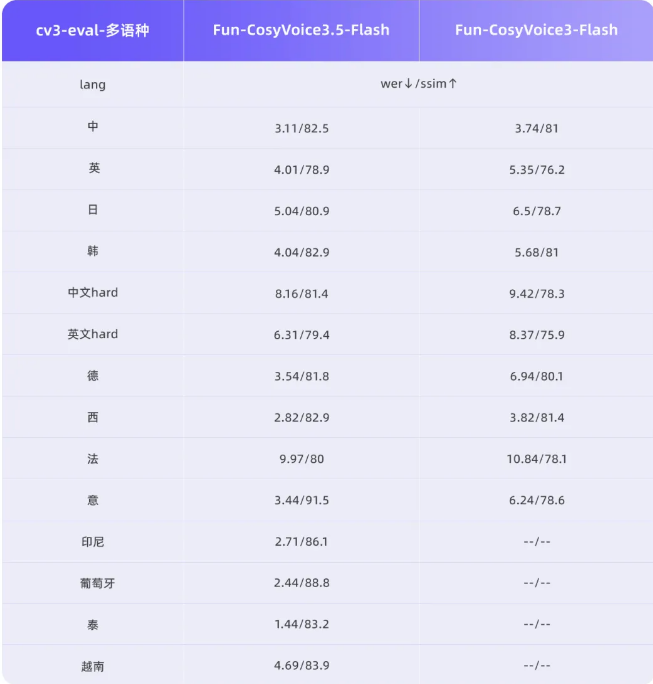
The secret lies in optimized architecture that prioritizes responsiveness without sacrificing quality. While slightly more proficient in English, the bilingual model maintains remarkable fluency in Chinese too. Unlike earlier systems that stumbled over long passages, VibeVoice can sustain 90 minutes of continuous speech without audible glitches or tonal inconsistencies.
"We've crossed an important threshold where synthetic speech keeps pace with human conversation," explains Microsoft's project lead. "The delay now measures shorter than most people's natural pause between sentences."
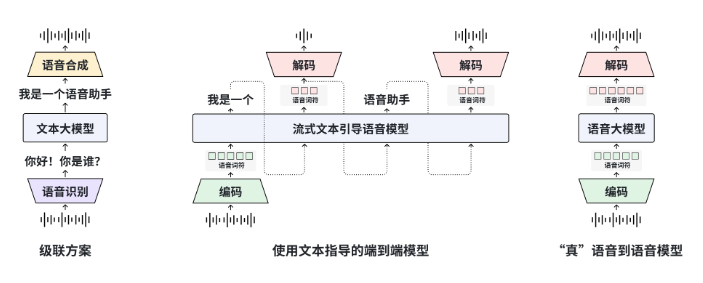
Multi-Voice Conversations Come Alive
Where the model truly shines is handling interactive scenarios:
- Supports up to four distinct voices simultaneously
- Maintains unique vocal fingerprints during extended dialogues
- Perfect for podcast simulations or virtual interview formats
The system tracks each speaker's rhythm and intonation patterns so convincingly that testers reported forgetting they weren't hearing human participants during multi-character exchanges.
Emotional Intelligence Under the Hood
Beyond technical specs, what sets VibeVoice apart is its nuanced emotional interpretation:
- Detects textual cues for anger, excitement or apology
- Adjusts pitch and cadence accordingly
- Even captures subtle shifts like hesitant pauses or emphatic stresses
The result? Synthetic voices that sound genuinely engaged rather than mechanically reciting words.
Small Package, Big Potential
At just 0.5B parameters - tiny by today's standards - the model offers practical advantages:
| Feature | Benefit |
|---|
Microsoft envisions integration into smart assistants, call center systems and accessibility tools where instant response matters most.
Key Points:
- Achieves 300ms response time - faster than human pause duration
- Maintains vocal consistency during 90-minute monologues
- Handles four-way conversations with distinct character voices
- Interprets emotional context from text cues
- Lightweight design enables on-device deployment
The model is now available on Hugging Face for developers to experiment with.