China's MOSS-Speech Breaks New Ground in AI Conversations
A Leap Forward in Natural AI Conversations
Fudan University's MOSS team has made waves in artificial intelligence with their groundbreaking MOSS-Speech system. Unlike traditional voice assistants that rely on converting speech to text and back again, this new model handles conversations entirely through sound - just like humans do.
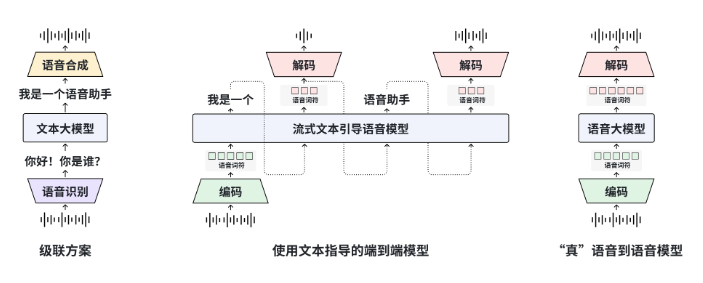
How It Works Differently
The secret lies in its clever "layer splitting" architecture. Instead of rebuilding everything from scratch, researchers kept the proven text capabilities of their original MOSS model frozen intact. They then added three specialized layers:
- A speech understanding layer that interprets vocal patterns
- A semantic alignment layer connecting meaning to sound
- A neural vocoder that generates natural-sounding responses
This elegant solution bypasses the clunky three-step process (speech-to-text → language processing → text-to-speech) used by Siri, Alexa and other digital assistants.
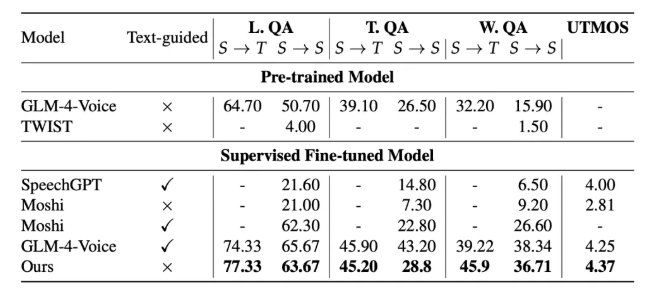
Performance That Surprises
The numbers tell an impressive story:
- Just 4.1% word error rate on complex speech tasks - better than Meta's SpeechGPT and Google AudioLM
- 91.2% accuracy recognizing emotions from tone of voice
- Nearly human-level 4.6 MOS score (out of 5) for Chinese speech quality
The team offers two versions: a studio-quality 48kHz edition and a lightweight 16kHz variant that runs smoothly on a single RTX4090 GPU with under 300ms delay - fast enough for real-time mobile apps.
What's Coming Next?
The researchers aren't resting on their laurels. By early 2026, they plan to release "MOSS-Speech-Ctrl" - a version users can direct with voice commands like "sound more excited" or "speak slower." The technology is already available for commercial licensing through GitHub, complete with tools for creating custom voices.
Key Points:
- First Chinese AI system enabling direct speech-to-speech conversations
- Achieves superior accuracy by preserving emotional nuance often lost in text conversion
- Lightweight version enables real-time use on consumer hardware
- Upcoming control features will allow vocal style adjustments mid-conversation