Meta's New Tool Spots Sneaky GPU Failures Before They Crash AI Training
Meta Tackles Silent GPU Failures That Sabotage AI Training
As artificial intelligence models grow exponentially larger, the GPU clusters powering them have become some of the most complex - and temperamental - computing systems ever built. Meta's AI research team recently unveiled a solution to one of the industry's trickiest problems: silent hardware failures that can derail weeks of expensive training runs.
The Hidden Threat in AI Infrastructure
Imagine spending $2 million training an AI model, only to discover halfway through that one malfunctioning graphics card contaminated your results. That's exactly what happens with "silent failures" - GPUs that appear operational but deliver degraded performance. Unlike web servers where you can simply add more capacity, AI training is vulnerable to these subtle hardware issues.
"A single problematic GPU can act like poison spreading through an entire cluster," explains Meta's technical documentation. "The gradients become corrupted, and you might not realize until days or weeks of computation are wasted."
How GCM Works Its Magic
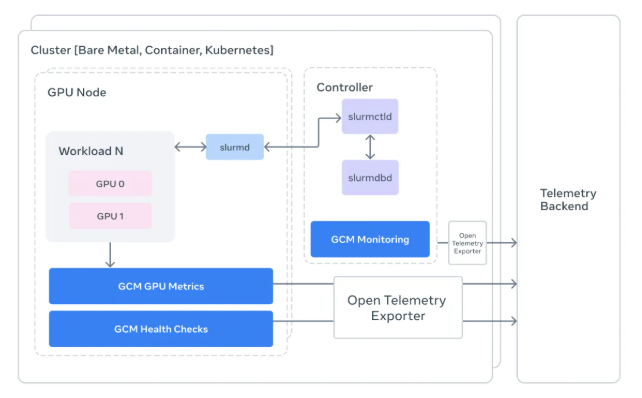
The newly open-sourced GPU Cluster Monitoring (GCM) toolkit serves as a translator between raw hardware data and the engineers who need actionable insights. Deeply integrated with the popular Slurm scheduler, it provides:
- Task-level visibility: Engineers can now trace power fluctuations or errors back to specific jobs rather than guessing which node might be causing trouble.
- Automated diagnostics: The system runs comprehensive checks before and after each task using NVIDIA's DCGM tools.
- Intuitive dashboards: Complex telemetry data gets converted into easy-to-read OpenTelemetry formats viewable in Grafana.
"Before GCM, spotting these issues was like finding a needle in a haystack," says one Meta engineer familiar with the project. "Now we get what amounts to a daily physical exam for every GPU in our fleet."
Why This Matters Beyond Meta
The timing couldn't be better as companies race to train ever-larger models:
- Training runs now commonly involve thousands of GPUs working for weeks straight.
- The cost of interrupted training grows exponentially with model size.
- Traditional monitoring tools weren't designed for these unique workloads.
By open-sourcing GCM, Meta provides smaller organizations access to monitoring capabilities previously limited to tech giants. Early adopters report catching hardware issues up to 80% faster than with conventional methods.
Key Points:
- 🕵️♂️ Detects stealthy failures: Catches GPUs that appear functional but underperform
- 🔗 Job-aware monitoring: Links hardware metrics directly to specific training tasks
- 💰 Saves millions: Prevents costly wasted computation from corrupted training runs
- 🚀 Open-source advantage: Makes enterprise-grade monitoring accessible to all