Meituan Unveils LongCat-Video Model for Advanced AI-Generated Content
Meituan Introduces Revolutionary Long Video Generation AI
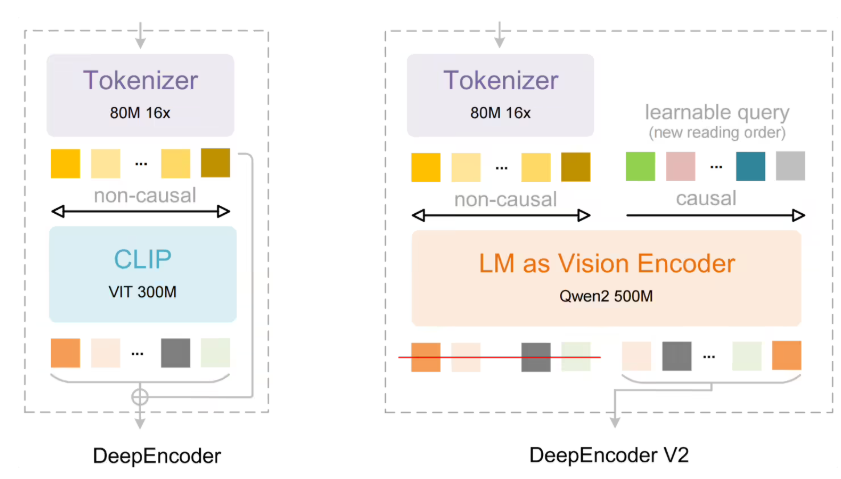
Meituan's research division has taken a significant leap in artificial intelligence with the release of LongCat-Video, a cutting-edge video generation model that promises to transform content creation workflows. This development marks a major milestone in the company's exploration of "world models" - AI systems designed to understand and simulate real-world dynamics.

Technical Architecture and Capabilities
The model is built on an advanced Diffusion Transformer (DiT) framework, integrating three core functionalities:
- Text-to-video generation at 720p resolution and 30fps
- Precise image-to-video conversion preserving original attributes
- Seamless video continuation extending clips coherently
What sets LongCat-Video apart is its innovative use of "conditional frame count" parameters that enable the system to intelligently distinguish between different input tasks while maintaining consistent output quality.
Breakthrough in Long-Form Content Creation
The most remarkable achievement is the model's ability to generate stable, coherent videos lasting up to 5 minutes - a significant advancement over previous systems limited to short clips. This capability addresses persistent challenges in AI video generation:
- Eliminates color drift across frames
- Prevents quality degradation over time
- Maintains consistent character actions and environments
The technological breakthrough holds particular promise for applications requiring extended simulations, such as autonomous driving systems and embodied AI platforms.
Performance Optimization
The development team implemented several innovations to enhance efficiency:
- Two-stage coarse-to-fine generation pipeline
- Block-sparse attention (BSA) mechanisms
- Advanced model distillation techniques These optimizations resulted in a 10.1x improvement in inference speed without compromising output quality.
Benchmark Results and Availability
Rigorous testing demonstrates that LongCat-Video achieves state-of-the-art (SOTA) performance across multiple metrics:
- Text-to-video alignment accuracy
- Visual fidelity scores
- Motion naturalness evaluations
The model has been made publicly available through GitHub and Hugging Face repositories, lowering barriers for both individual creators and enterprise users.
Key Points:
- First commercial-grade AI capable of generating stable 5-minute videos
- Combines three generation modes under unified architecture
- Sets new benchmarks for open-source video generation quality
- Potential applications span entertainment, education, and industrial simulation