DeepSeek's New OCR Model Reads Documents Like Humans Do
DeepSeek-OCR2: A Smarter Way for Machines to Read
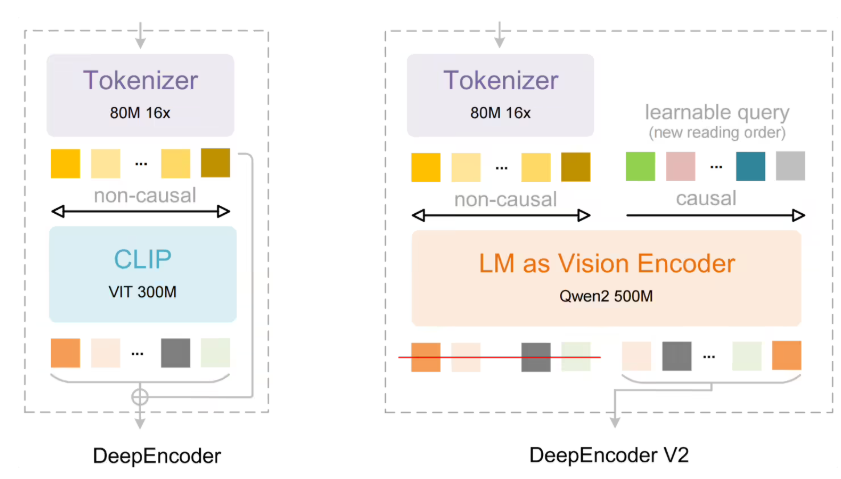
Imagine flipping through a dense research paper - your eyes naturally jump between headings, tables, and key paragraphs rather than reading every word sequentially. That's exactly how DeepSeek's new OCR model now operates.
The recently launched DeepSeek-OCR2 represents a significant leap forward in document recognition technology. At its core lies the innovative DeepEncoder V2, which replaces rigid left-to-right scanning with intelligent "visual causal flow" processing.
How It Works Differently
Traditional OCR systems treat documents like simple grids, processing content mechanically from top-left to bottom-right. This often leads to jumbled outputs with tables misread as plain text or formulas losing their structure.
DeepSeek-OCR2 changes the game by:
- Analyzing document layouts semantically before recognition
- Dynamically adjusting its reading path based on content importance
- Preserving logical relationships between different elements
The system essentially teaches machines to "skim" documents first - identifying structural patterns humans instinctively recognize before diving into detailed text extraction.
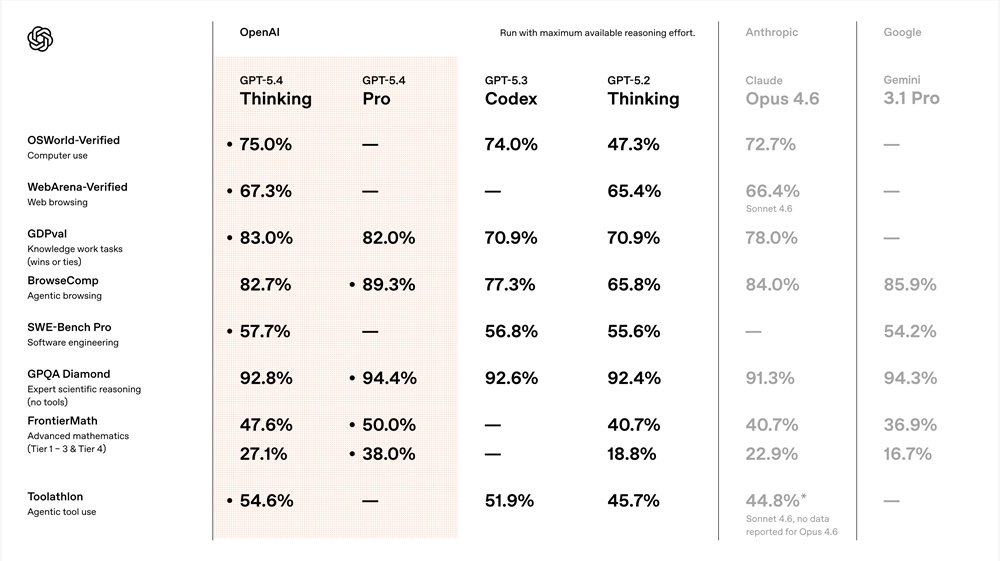
Measurable Improvements
Independent benchmark tests tell a compelling story:
- 91.09% accuracy on OmniDocBench v1.5 (3.73% better than v1)
- Fewer sequencing errors in complex layouts (measured by edit distance)
- Reduced repetition rates during batch processing of PDFs
The model achieves these gains while maintaining computational efficiency through its mixture-of-experts (MoE) architecture - proving you don't always need brute-force power for smarter results.
Real-World Impact
For businesses drowning in paperwork, these technical advances translate to:
- More reliable digitization of financial reports and legal contracts
- Better preservation of scientific formulas and research data structures
- Reduced manual correction time for archival projects
The technology shows particular promise for Asian language documents where complex layouts traditionally challenged OCR systems.
Key Points:
- Human-like reading patterns: Processes content based on meaning rather than fixed sequences
- Structural awareness: Maintains relationships between tables, text blocks and formulas
- Efficient architecture: Delivers accuracy improvements without heavy resource demands
- Practical benefits: Reduces error rates in batch processing scenarios