Google's Gemini 3.1 Flash-Lite: Faster, Smarter, But Pricier
Google's Latest AI Model Delivers Speed and Smarts - At a Price
Google DeepMind has rolled out its newest AI contender: Gemini 3.1 Flash-Lite. This lightweight model isn't just fast - it's smart too, marking a significant step up from previous versions while maintaining blazing processing speeds.

Performance That Turns Heads
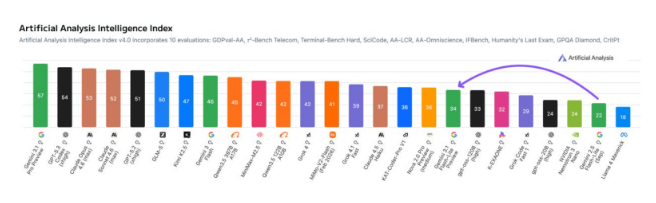
The numbers tell an impressive story. Clocking in at over 360 tokens per second with responses averaging just 5.1 seconds, Gemini 3.1 Flash-Lite doesn't sacrifice speed for capability. Its intelligence score jumped 12 points to 34 on industry benchmarks, while earning a respectable 1432 Elo rating on Arena.ai's competitive leaderboard.
Where it really shines is handling complex tasks. Scoring 86.9% on the challenging GPQA Diamond test and achieving 76.8% accuracy on MMMU-Pro benchmarks puts it ahead of heavyweight competitors like Claude Opus and Kimi models.
Flexibility Meets Power
Developers get an interesting new tool with this release - customizable "thinking depth." This means the same model can handle everything from quick translations to building intricate user interfaces by adjusting how deeply it processes information.
The Cost of Progress Comes Due
The advancements don't come cheap though. Google has implemented substantial price hikes:
- Input token costs: Now $0.25 per million (up from previous rates)
- Output tokens: Skyrocketed from $0.40 to $1.50 per million
The nearly threefold increase reflects the growing pains of balancing speed with sophisticated reasoning capabilities.
What This Means for Developers
The model is already available for testing through Google AI Studio and Vertex AI platforms. Its release signals an industry shift - we're moving beyond simple price wars into an era where accessible high-performance AI commands premium pricing.
Key Points:
- Speed maintained: Processes >360 tokens/sec with ~5 sec response times
- Smarter processing: Significant intelligence gains across benchmarks
- Flexible applications: Customizable depth suits various complexity levels
- Higher costs: Pricing nearly triples previous generation models
- Market shift: Signals move toward premium performance models