Moonlight AI的Kiwi-do模型以视觉物理能力惊艳亮相
Moonlight AI发布突破性多模态模型
这一进展引发了AI界的广泛热议,Moonshot AI似乎悄然推出了"Kiwi-do"——一个展现卓越视觉推理能力的精密新模型。该模型的出现在Moonshot最近完成35亿美元C轮融资后不久。
意外发现引发轰动
该模型最初意外现身基准测试平台LmArena,一位眼尖的研究人员注意到了其出色的性能指标。当被问及来源时,Kiwi-do自称来自"Moonshot AI"——这加剧了猜测:它可能是备受期待的K2-VL多模态系统的早期版本。
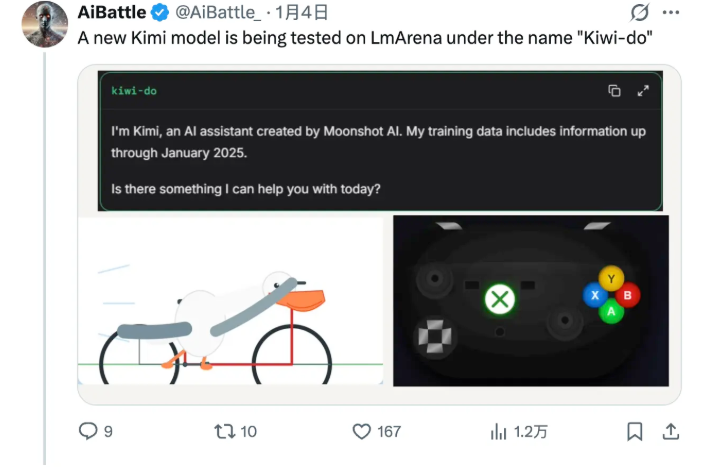
Kiwi-do特别引人注目之处在于其训练数据截止到2025年1月——按行业标准来看相当新近。但真正让研究人员兴奋的是该模型在严苛的视觉物理理解测试(VPCT)中的表现。
突破多模态边界
"VPCT结果表明这与现有模型有本质区别,"与Moonshot无关的AI研究员林伟博士解释道,"这不仅仅是渐进式改进——我们看到系统在连接视觉输入与物理推理方面实现了质的飞跃。"
这对从技术文档分析到实时仪表板解读等实际应用可能意义重大——当前系统在这些领域常常表现不佳。

进度超前?
Moonshot此前曾表示计划在本季度晚些时候推出增强的多模态功能,可能命名为K2.1或K2.5。Kiwi-do的突然出现让人质疑开发进度是否比预期更快。
对比测试显示Kiwi-do与Moonshot现有的K2-Thinking模型存在明显差异,特别是在SVG渲染任务中。这些差异足以证实它们是不同的系统。
这对AI发展意味着什么
科技界正密切关注Kiwi-do是否代表:
- 即将推出的K2系列的内部测试版本
- 针对视觉推理的专业分支
- Moonshot产品线中全新的存在
有一点似乎可以确定:如果这些早期迹象属实,我们可能正在见证AI系统真正理解——而不仅仅是处理——周围视觉世界的重大进步。
关键要点:
- 意外亮相:Kiwi-do模型在基准测试平台上表现异常出色
- 视觉物理突出:在复杂的VPCT评估中展现出非同寻常的强大性能
- 商业潜力:可增强文档分析和数据可视化等实际应用
- 开发之谜:可能意味着向计划中的K2系列发布的进程加速