DeepSeek发布30亿参数OCR模型,实现高效文档解析
DeepSeek突破性OCR模型树立新标杆
人工智能研究公司DeepSeek发布了DeepSeek-OCR,这是一套尖端的光学字符识别系统,标志着文档处理技术的重大飞跃。该新型模型采用端到端架构,融合了计算机视觉与语言处理能力,旨在实现最高效率。
技术规格与性能表现
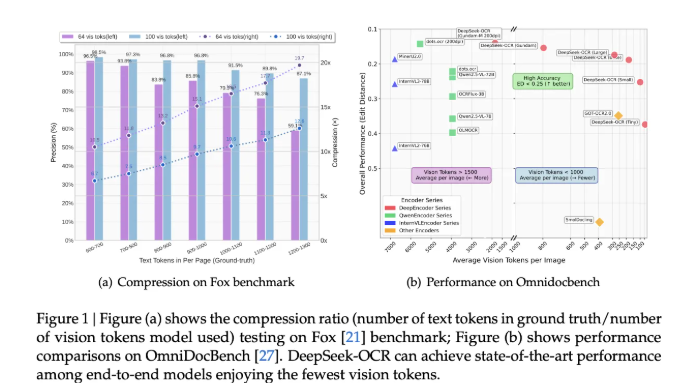
该模型在严格的Fox基准测试中实现了97%的解码准确率,即使在极端压缩比下仍保持强劲性能。测试显示其在10倍压缩时结果可靠,并在20倍压缩时仍保持有用特性。在OmniDocBench基准测试中,DeepSeek-OCR以显著更少的视觉令牌超越了传统模型。
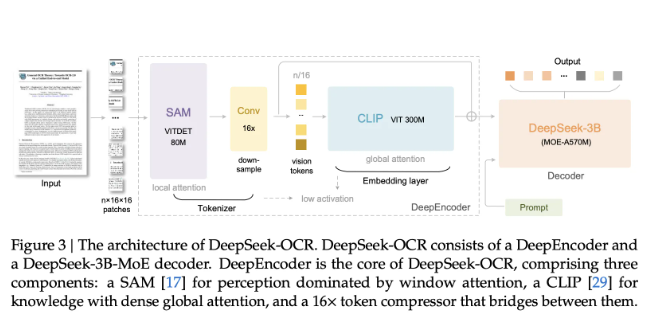
架构包含两大核心组件:
- DeepEncoder:采用基于SAM的局部感知窗口注意力的高分辨率视觉编码器
- DeepSeek3B-MoE-A570M:总参数量达30亿(每个令牌激活570M)的混合专家解码器
灵活的部署选项
DeepSeek-OCR提供多种操作模式:
- 标准模式:Tiny、Small、Base、Large(不同分辨率/令牌数)
- 动态模式:Gundam和Gundam-Master根据页面复杂度调整令牌预算
训练过程包括:
- 初始DeepEncoder训练用于下一令牌预测
- 跨多节点的全系统训练
- 每日超过200,000页的生产级生成规模
开发团队建议大多数应用从Small模式开始,仅在处理密集文本或高令牌数时才切换至Gundam模式。

行业影响与获取方式
此次发布标志着文档AI技术的重大进步,潜在应用领域包括:
- 法律文件处理
- 医疗记录数字化
- 财务报表分析
- 历史档案保存
The model's papers and implementation are available through:
The model's papers and implementation are available through:
核心亮点:
🌟 Fox基准测试中达97%准确率并保持高效压缩\ 📊 OmniDocBench上超越传统模型\ 🔧 多种分辨率模式适应文档复杂度\ 💻 开源实现已开放获取