美团新AI模型实现类人视觉与听觉能力
美团开创统一感知AI新纪元
想象一个不仅能阅读文本,还能像人类一样自然观察图像和聆听语音的AI。这正是美团通过最新发布的LongCat-Next模型实现的突破,标志着机器理解世界方式的重大飞跃。
突破性技术解析
这项创新的核心是DiNA架构(离散原生自回归),它将所有类型的输入——无论是文字、图片还是声音——视为相同基础构建块的不同表现形式。其独特之处在于:
- 一体化系统:不再为不同媒体类型配备独立机制,LongCat-Next采用统一的处理方法
- 双重能力:相同的数学方法使模型既能解读信息又能无缝创作新内容
- 空间优化设计:其视觉压缩技术可将图像数据缩小28倍而不丢失关键细节,这对文档分析等任务尤为重要
超越专家预期的实际表现
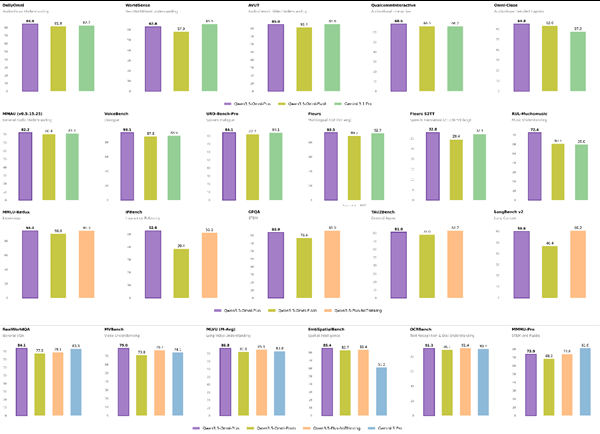
LongCat-Next不仅在理论上令人印象深刻,在实际测试中也超越了专用模型:
- 文档理解:在从复杂版面和密集文本中提取信息方面胜过专用视觉模型
- 数学能力:在视觉数学解题测试中获得83.1的高分
- 语音模仿:可实时生成语音同时保持行业领先的文本理解能力(在C-Eval基准测试中得分86.80)
"最令人惊叹的是",一位行业分析师指出,"它打破了将连续数据(如图像)转换为离散标记必然牺牲质量的假设。这些结果证明了相反的情况。"
对未来AI发展的意义
这项技术的真正价值在于创建了AI感知的通用语言。当机器能像处理文本一样自然地处理视觉和听觉信息时,我们将迎来:
- 更直观的人机交互
- 真正理解环境的智能助手
- 无需特殊编程即可解读复杂图表或示意图的系统
美团已公开LongCat-Next模型及其dNaViT标记器,为开发者提供了强大工具,可构建与物理世界交互更自然的AI系统。
核心亮点:
- 原生多模态处理:首个将视觉、语音和文本视为平等输入的AI
- 经证实的性能:在多项基准测试中超越专用模型
- 开放访问:技术现已开放供开发者构建应用