Qwen3.5-Omni以多模态掌控力开启AI新时代
AI能力的飞跃
通义实验室发布了突破性的Qwen3.5-Omni模型,标志着人工智能发展的重大里程碑。与传统局限于文本交互的AI助手不同,这款新模型凭借其先进的多模态理解能力,架起了数字世界与物理世界的桥梁。

关键性技术突破
Qwen3.5-Omni卓越表现背后的秘密在于其创新架构:
- 混合注意力MoE系统:升级版的"思考者"组件可处理长达256K的上下文——相当于解析10小时音频或1小时视频内容而不丢失细节。
- ARIA技术:"对话者"组件的新方法解决了常见语音合成问题,同时实现极具人性化的实时语音控制。
令人惊艳的实际应用
Qwen3.5-Omni的独特之处不仅在于技术参数,更在于这些技术如何转化为现实应用:
- 智能内容分析:该模型能观看视频并生成带有精确时间戳的动作描述、音乐变化和镜头转换记录。
- 自然对话:它能区分用户是真正打断发言还是仅仅清嗓子——这是大多数AI难以处理的微妙但重要的区别。
- 个性化声音创建:上传简短音频样本,系统就能以惊人自然度克隆113种语言版本的用户声音。
- 代码生成:向它展示演示应用功能的视频,它就能生成可运行的Python代码或前端原型。
可用性与选项
该模型目前通过阿里云百炼平台提供三个版本(Plus、Flash、Light),用户可通过ModelScope社区获取实时API访问权限。
核心亮点:
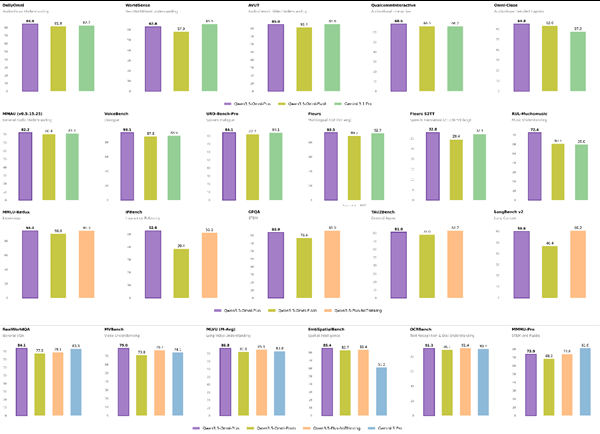
- 在各种测试中获得215项尖端成果
- 在通用音频理解方面超越Gemini-3.1Pro
- 保持视觉和文本处理的顶级性能
- 引入突破性ARIA技术实现自然语音合成
- 支持从声音克隆到视频分析的多种实际应用