DeepSeek V3 超越 Claude 3.5 在 AI 性能测试中
DeepSeek V3 超越 Claude 3.5 在 AI 性能测试中
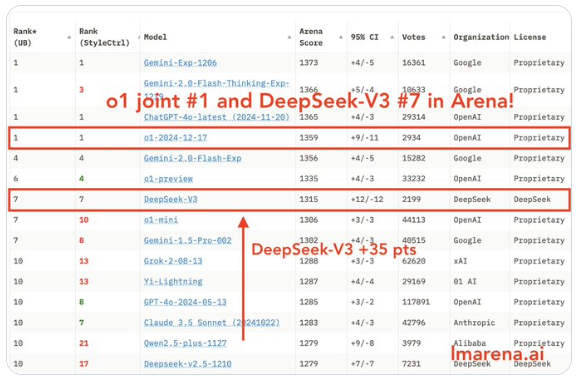
最近,国产大模型 DeepSeek V3 因其杰出的表现而在 AI 领域引起了广泛关注。作为唯一进入前十名的开源模型,它不仅超越了 o1-mini,还在编程和数学等多个领域超越了 Claude 3.5 Sonnet。为了验证它的实际能力,进行了系列的真实比较测试。
理解能力测试
在基本理解能力测试中,两个模型表现出不同的特征。当面临中文谜语“晓明的母亲有三个孩子”时,DeepSeek V3 表现优异,不仅回答正确,还进行了自我验证。然而,在英文双关语“愚人节”中,它未能把握语言的细微差别,而 Claude 3.5 Sonnet 则轻松应对。

逻辑推理测试
逻辑推理测试也揭示了有趣的结果。当面对经典的逻辑陷阱“傻瓜酒吧”时,两个模型都出现了判断错误。然而,在“反向咒语”类型的问题中,两者都表现出色,成功识别了汤姆·克鲁斯与其母亲之间的关系。
数学问题解决
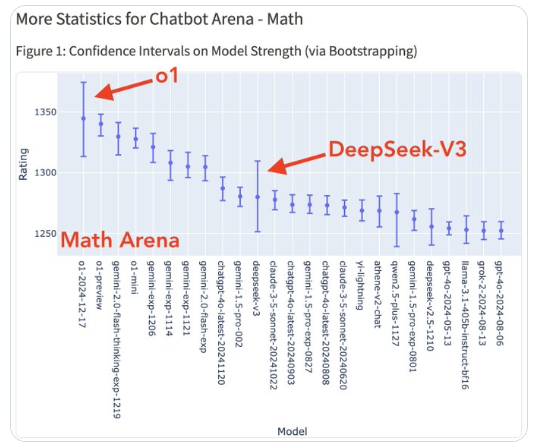
在研究生入学考试的数学问题竞赛中,DeepSeek V3 展示了更强的数学能力。它不仅对表面积分和 高斯定理 的应用进行了详细分析,还得出了正确答案。相反,尽管 Claude 3.5 Sonnet 的思路清晰,但最终的计算结果却是错误的。
编程能力
在编程能力的比较中,DeepSeek V3 在网站创建测试中获胜。这个结果确认了它在当前排名中的杰出表现。
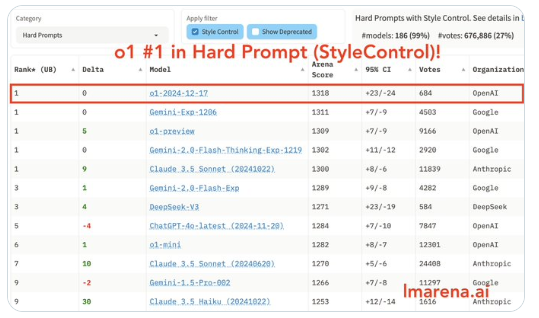
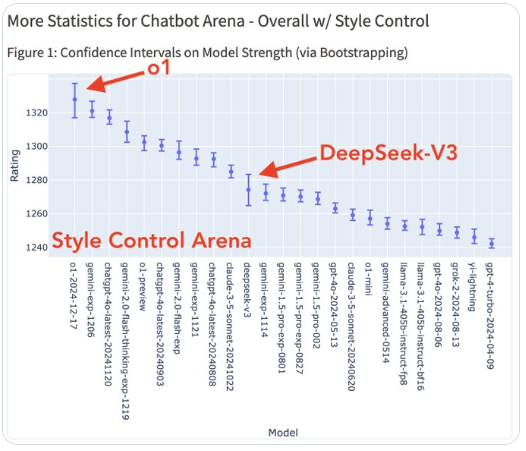
值得一提的是,随着 o1 的完整版的推出,AI 领域的格局又一次发生了变化。o1 凭借绝对优势登顶,几乎垄断了除创意写作外的所有类别的第一名。
结论
这一系列测试表明,中国自主研发的大模型 正在快速赶上国际领先水平。DeepSeek V3 的表现证明它在特定领域具有与顶尖模型竞争的实力,为国内 AI 技术的发展注入了新的信心。
关键点
- DeepSeek V3 在理解、逻辑和数学测试中超越了 Claude 3.5 Sonnet。
- 该模型通过在网站创建中的表现展示了其编程技能。
- o1 的出现改变了 AI 竞争格局,它在各个类别中占据主导地位。
- DeepSeek V3 的表现突显了中国国内 AI 技术的快速进步。