字节跳动与香港高校开源DreamOmni2 AI图像编辑器
字节跳动与香港高校发布开源AI图像编辑器DreamOmni2
在AI驱动图像编辑领域的重大进展中,字节跳动联合香港中文大学、香港科技大学和香港大学的研究人员开源了DreamOmni2。这一创新系统在多模态AI理解方面实现了飞跃,特别是在处理抽象视觉概念上。
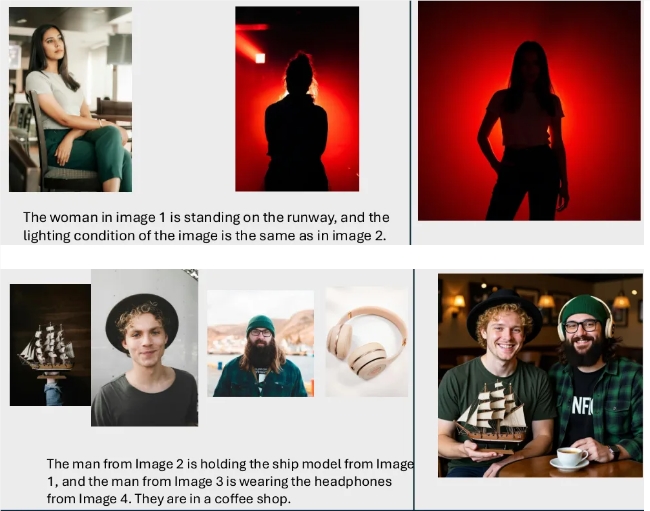
突破抽象概念壁垒
新发布的系统解决了AI图像处理中长期存在的挑战——以往模型难以解读关于风格、材质和光照的抽象指令。DreamOmni2引入了突破性能力:
- 同时处理文本指令和参考图像
- 提升编辑过程中保持图像一致性的准确度
- 类人类协作的自然交互流程
"这不只是另一个图像生成器,"港中大首席研究员李伟博士解释道,"我们创造的AI能真正理解跨多输入模态的艺术意图。"
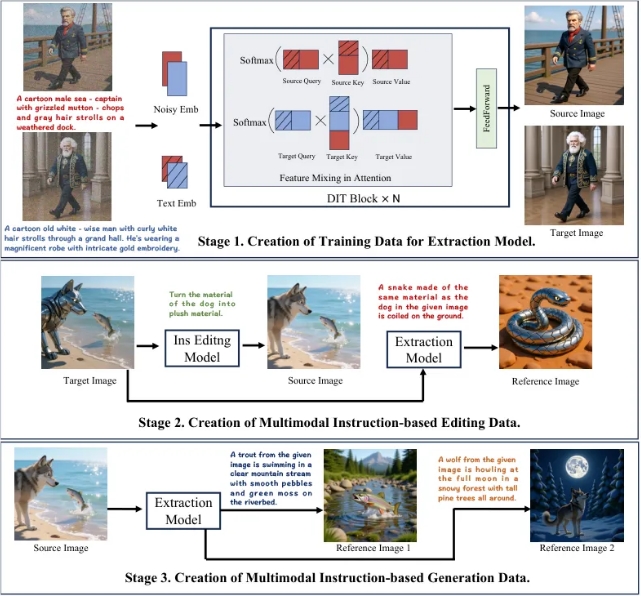
三阶段训练流程
开发团队采用了创新的训练方法:
- 提取模型训练:教导AI识别图像中的特定元素或抽象属性
- 多模态数据生成:创建结合源图像、指令、参考图像和目标输出的综合训练样本
- 数据集扩展:通过额外提取和组合流程进一步优化系统
技术创新
该系统融合了多项新颖技术方案:
- 索引编码方案:在复杂工作流中精确定位多个输入图像
- 位置编码偏移量:处理过程中保持空间关系
- 视觉语言模型(VLM)桥梁:高效将用户指令转化为可执行编辑
"VLM组件至关重要,"字节跳动工程师张涛指出,"正是它让系统能在你展示莫奈参考图时说'让它更印象派'时理解意图。"
性能基准测试
独立测试显示DreamOmni2:
- 超越所有同类开源模型
- 接近顶级商业解决方案能力
- 对复杂指令展现卓越准确性
- 最小化其他系统中常见的伪影问题
此次开源发布包含标准化评估指标,为研究人员提供未来开发的一致基准。
行业影响
该技术的开放有望:
- 普及先进AI图像编辑能力
- 加速多模态AI系统研究
- 建立指令遵循准确度的新标准 "我们正见证创意AI新时代的开端,"斯坦福大学教授Elena Rodriguez评论道,"像DreamOmni2这样的系统模糊了工具与创意伙伴的界限。" 完整框架现已在GitHub以开源许可发布。 ### 核心要点:
- 多模态AI突破可同时理解文本与视觉参考
- 新颖三阶段训练流程实现抽象概念理解
- 超越现有开源方案并接近商业品质
- 开源版本包含标准化评估基准
- 有望变革跨行业创意工作流