DeepSeek全新OCR模型实现类人化文档阅读
DeepSeek-OCR2:更智能的机器阅读方案
想象翻阅一篇密集的研究论文时——你的视线会自然地在标题、表格和关键段落间跳转,而非逐字顺序阅读。这正是DeepSeek新OCR模型的运作方式。
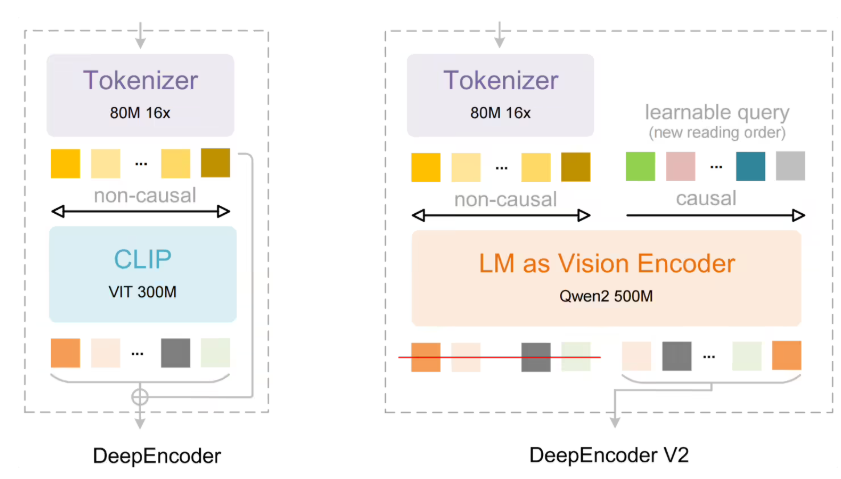
最新发布的DeepSeek-OCR2代表着文档识别技术的重大飞跃。其核心是创新的DeepEncoder V2架构,用智能的"视觉因果流"处理取代了僵化的从左到右扫描模式。
差异化工作原理
传统OCR系统将文档视为简单网格,机械地从左上到右下处理内容。这常导致输出混乱——表格被误读为纯文本或公式结构丢失。
DeepSeek-OCR2通过以下方式改变游戏规则:
- 在识别前语义化分析文档布局
- 根据内容重要性动态调整阅读路径
- 保持不同元素间的逻辑关系
该系统本质上教会机器先"略读"文档——像人类一样本能识别结构模式,再进行详细文本提取。
可量化的进步
独立基准测试结果令人信服:
- OmniDocBench v1.5准确率达91.09%(较v1提升3.73%)
- 复杂版式中的排序错误减少(通过编辑距离测量)
- PDF批量处理的重复率降低
该模型通过混合专家(MoE)架构在保持计算效率的同时实现这些提升——证明更智能的结果未必需要蛮力计算。
实际影响
对这些技术突破,被文书淹没的企业将获得:
- 财务报告和法律合同更可靠的数字化转换
- 科学公式和研究数据结构更好保留
- 档案项目人工校对时间大幅缩减
该技术对亚洲语言文档尤其有价值——传统OCR系统一直难以应对其复杂版式。
核心亮点:
- 类人阅读模式:基于内容含义而非固定顺序处理
- 结构感知能力:保持表格、文本块与公式间的关系
- 高效架构设计:无需沉重资源消耗即可提升精度
- 实用优势:显著降低批量处理的错误率