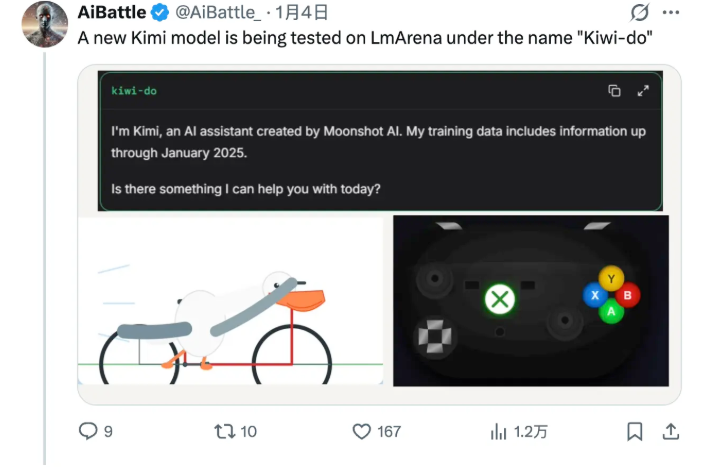
LLaVA-OneVision-1.5 在基准测试中超越Qwen2.5-VL
LLaVA-OneVision-1.5 为开源多模态模型树立新标杆
AI领域迎来了LLaVA-OneVision-1.5,这是一款完全开源的多模态模型,在视觉语言理解方面实现了重大飞跃。作为LLaVA(大型语言与视觉助手)系列历时两年开发的成果,这一最新版本展现出优于Qwen2.5-VL等成熟模型的性能表现。
创新的三阶段训练框架
该模型的开发遵循精心设计的三阶段训练流程:
- 语言-图像对齐预训练:将视觉特征转换为语言学词嵌入
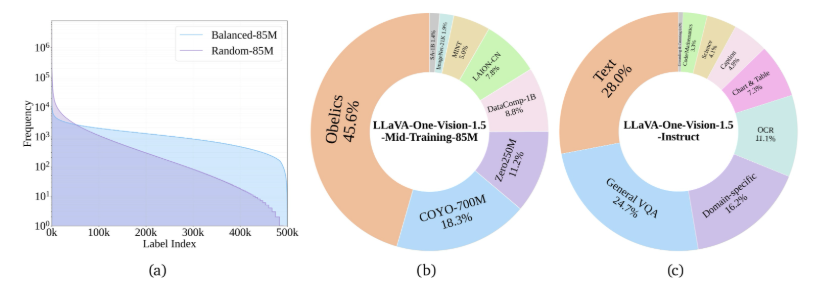
- 高质量知识学习:通过8500万样本训练增强视觉与知识能力
- 视觉指令微调:针对复杂视觉指令的专业化训练
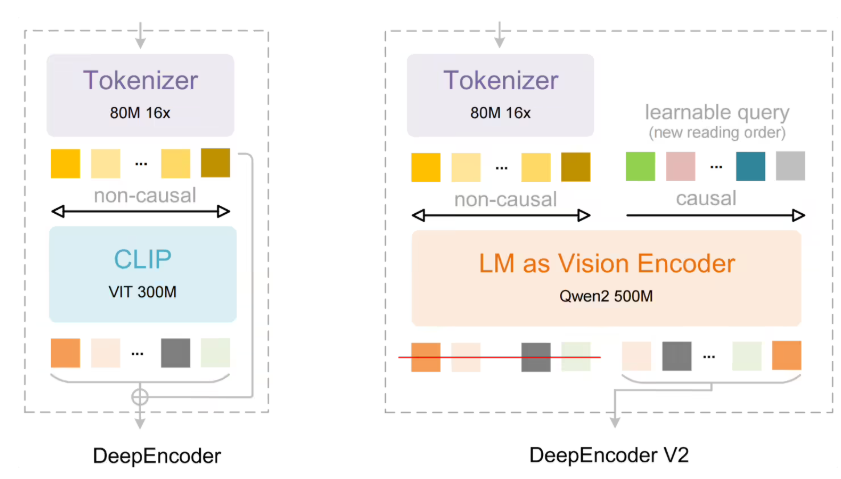
突破性的效率提升
开发团队实施了多项创新以优化训练过程:
- 离线并行数据封装实现11:1压缩比
- 完整训练周期仅需3.7天
- 采用RICE-ViT作为视觉编码器,提供卓越的文档文本处理能力
该模型的区域感知能力使其特别适合需要精细视觉理解的任务。
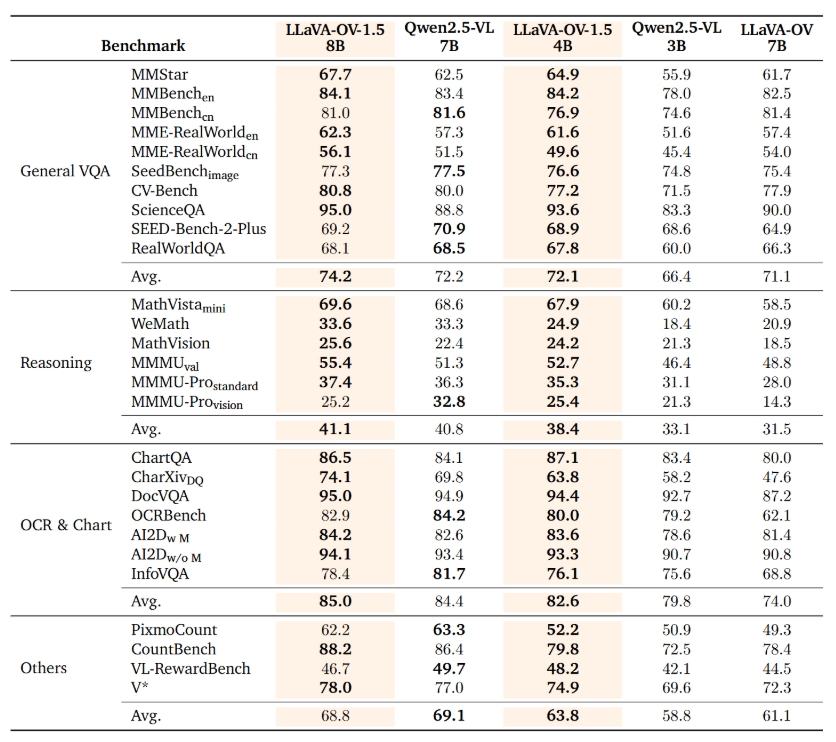
基准测试全面领先
80亿参数版本展现出非凡性能:
- 在27项不同基准测试中超越Qwen2.5-VL
- 采用"概念平衡"采样策略确保任务表现一致性
可处理图像、视频和文档等多种输入类型
该项目保持完全透明性,相关资源已在GitHub和Hugging Face平台开放。
核心亮点:
✅ 超越专有替代方案的完全开源多模态架构 ✅ 革命性的三阶段训练方法论 ✅ 通过创新数据处理实现前所未有的效率提升 ✅ 经基准验证优于竞品的卓越性能