阿里巴巴Z-Image Turbo以惊人效率加速AI艺术创作
阿里巴巴轻量级图像生成器性能超越庞大竞品
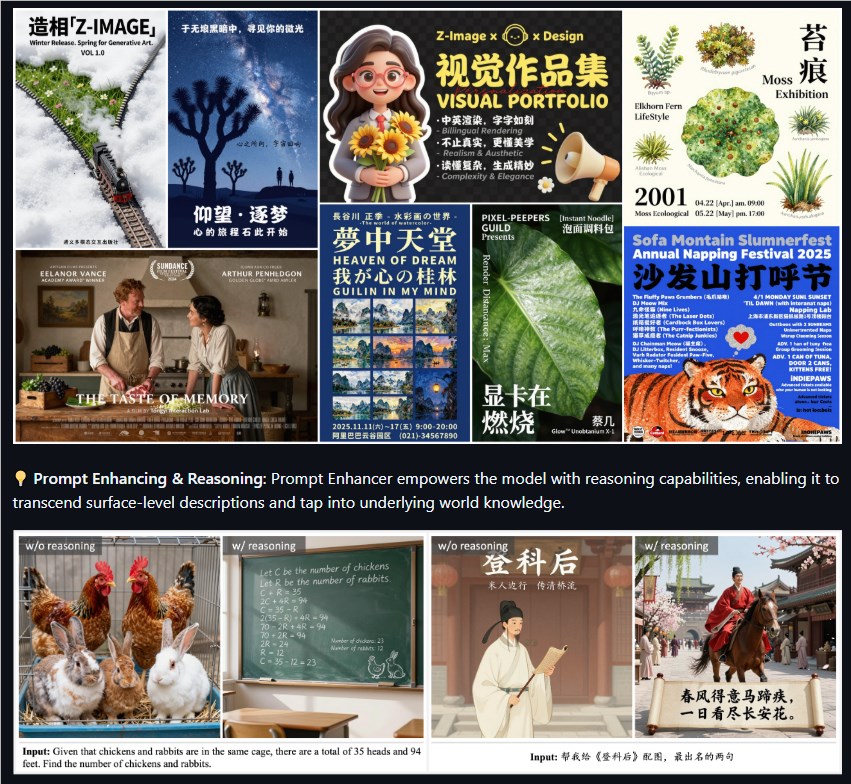
想象一下:用游戏PC仅需2.3秒就能生成1024×1024像素的霓虹汉服细节肖像。这正是阿里巴巴通义实验室昨晚展示的新Z-Image-Turbo模型实现的场景——在RTX 4090显卡上仅消耗13GB显存就完成了这一壮举。

小身材大能量
Z-Image的真正非凡之处不仅在于功能,更在于其高效性:
- 轻量运行: 在RTX 3060等仅6GB显存的普通硬件上流畅运作
- 中文提示词精通: 能理解复杂的嵌套描述,甚至修正逻辑矛盾
- 照片级细节: 捕捉皮肤纹理和玻璃反光等常令其他模型困惑的微妙元素
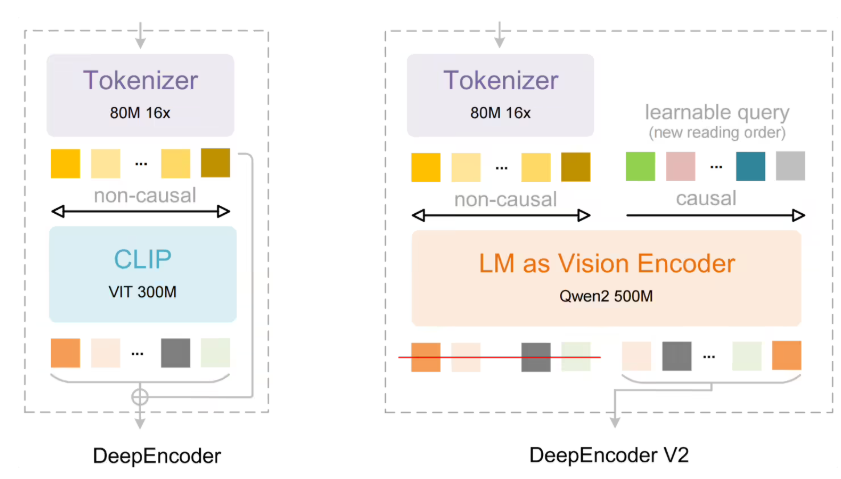
秘诀何在?创新的S3-DiT架构将文本、视觉语义和图像标记作为单一数据流处理。这种精简方法仅使用竞品三分之一的参数量,却能产出相当——有时更优——的效果。
democratizing AI艺术创作民主化
团队并未止步于生成能力。他们还发布了Z-Image-Edit,实现基于自然语言的图像修改——过去这需要Photoshop技巧。想换头像或改背景?描述需求即可。
虽然阿里巴巴尚未确认完全开源计划,但该模型已通过ModelScope和Hugging Face开放访问。随着pip简易安装的推出和企业API定价即将公布,商业竞争对手可能需要重新制定策略。
这一进展标志着生成式AI艺术工具的转折点。当专业级成果能在日常硬件上无需海量计算资源即可实现时,创意可能性将呈指数级扩展。
问题不在于你是否会尝试Z-Image——而在于你的首件创作会是什么。
项目地址: https://github.com/Tongyi-MAI/Z-Image
关键要点:
- 效率突破: 以少量参数匹配大型模型的输出质量
- 硬件普适性: 从RTX 3060起的消费级GPU皆可运行
- 中文语言优势: 擅长解析复杂提示词
- 开放获取: 目前已通过主流AI平台开放访问