Xiaohongshu Unveils FireRedTTS-2 for AI Podcast Production
Xiaohongshu Advances AI Audio with FireRedTTS-2 Launch
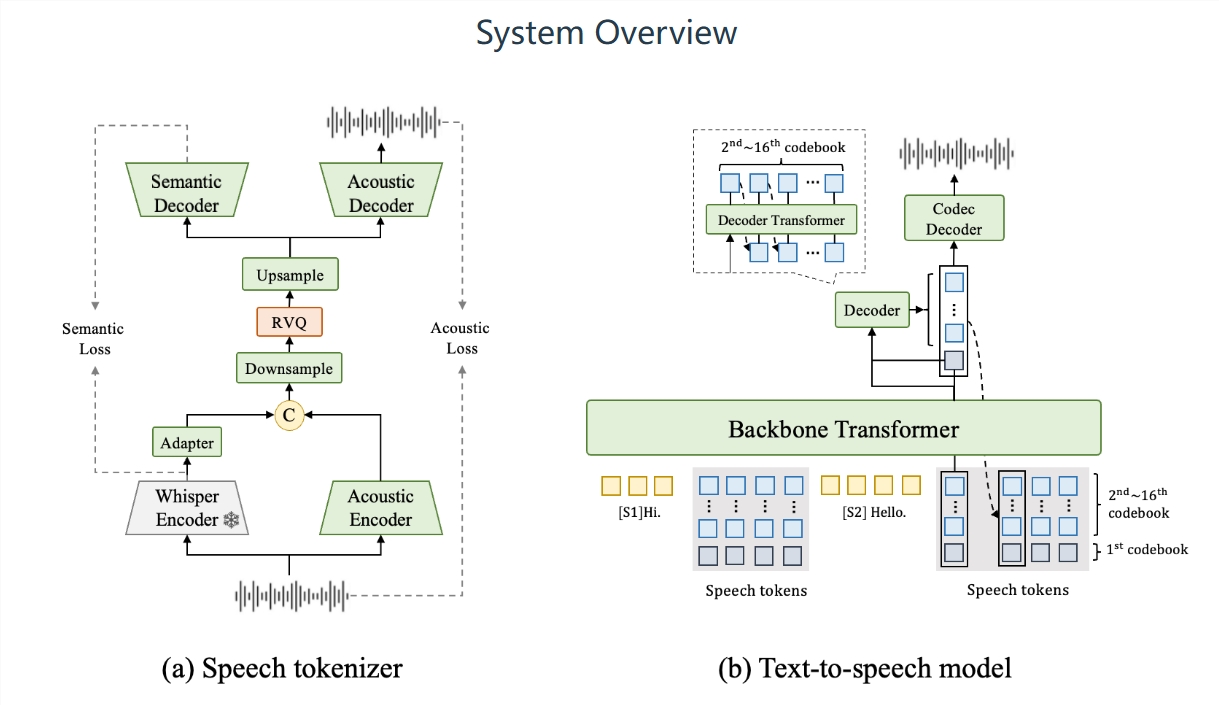
The Xiaohongshu ZhiChuang Audio Technology Team has unveiled FireRedTTS-2, a significant upgrade to its dialogue synthesis technology designed specifically for AI podcast production. This next-generation model addresses critical limitations in current solutions, including pronunciation accuracy, speaker switching stability, and prosody naturalness.
Technical Breakthroughs
The upgraded architecture features:
- Enhanced discrete speech encoder for improved audio quality
- Dual Transformer model for coherent speech generation
- Low-frame-rate processing that boosts synthesis speed by 30%
- Multi-language support (Chinese, English, Japanese, Korean, French)
In benchmark tests, FireRedTTS-2 demonstrated 15% higher naturalness scores compared to industry standards while maintaining real-time processing capabilities.
Voice Cloning Innovation
A standout feature is the model's ability to:
- Clone voices from just one sentence samples
- Preserve unique speaker characteristics (pitch, cadence, emotional tones)
- Generate multi-speaker dialogues with seamless transitions
This positions the open-source solution as a viable alternative to proprietary systems like Amazon Polly or Google WaveNet.
Practical Applications
The technology enables:
- Automated podcast production with human-like hosts
- Localized voiceovers for global content distribution
- Accessible media creation for non-technical users
The team has published technical details on arXiv and released the codebase on GitHub.
Future Development Roadmap
Planned enhancements include:
| Feature | Target Q1 2026 |
|---|
The technology could disrupt the $3.2B voice synthesis market by making professional-grade tools accessible to independent creators.
Key Points:
✅ Industrial-Grade Synthesis: Delivers studio-quality podcast audio without professional recording equipment
✅ Cost-Efficient: Reduces voiceover production costs by up to 80% compared to human recordings
✅ Rapid Deployment: Achieves voice customization with under 10 seconds of sample audio