Tiny AI Model Packs a Punch, Outperforms Giants
Small Model, Big Impact: Liquid AI's Latest Breakthrough
In a surprising holiday announcement, edge AI startup Liquid AI unveiled their experimental LFM2-2.6B-Exp model on Christmas Day. What makes this release remarkable isn't its size - at just 2.6 billion parameters it's practically petite by today's standards - but rather its outsized performance that's challenging much larger competitors.
Reinventing Reinforcement Learning
The secret sauce? Pure reinforcement learning (RL) optimization without the usual training wheels of supervised fine-tuning or teacher model distillation. This streamlined approach builds on Liquid AI's second-generation hybrid architecture that cleverly combines short-range gated convolution with grouped query attention (GQA). The result? A lean, mean reasoning machine that handles a generous 32K context length while staying nimble enough for smartphones and IoT devices.
"We're particularly excited about its potential for agent workflows and creative applications," shared a Liquid AI spokesperson. The model shines in RAG retrieval, data extraction, and surprisingly fluid multi-turn conversations.
Benchmark-Busting Performance
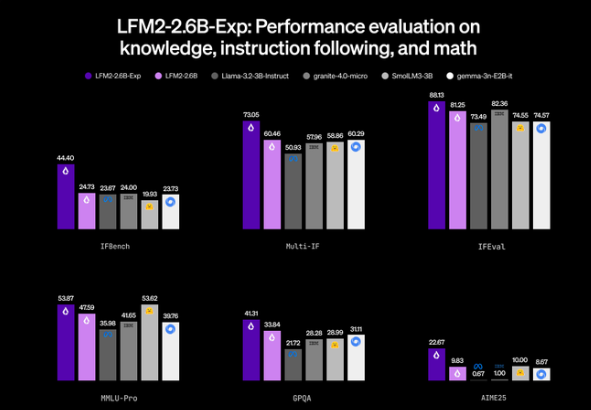
The numbers tell an impressive story:
- Instruction Following: Left DeepSeek R1-0528 (with 263x more parameters) eating its dust
- Graduate-Level Knowledge: Scored ~42%, putting traditional 3B models to shame
- Mathematical Reasoning: Topped 82%, beating out Llama3.23B and Gemma3 series
The real kicker? It processes information twice as fast as competitors on standard CPUs while sipping power like an energy-efficient smartphone app.
Democratizing Edge AI
In keeping with the holiday spirit of giving, Liquid AI has made LFM2-2.6B-Exp fully open source on Hugging Face. This move could accelerate edge AI adoption dramatically - imagine having research assistant-level smarts running locally on your phone without draining battery or compromising privacy.
The implications are tantalizing: if small models can achieve this level of performance through intelligent training rather than brute-force scaling, we might be entering a new era where powerful AI fits comfortably in our pockets rather than requiring massive cloud infrastructure.
Key Points:
- Tiny 2.6B parameter model outperforms giants hundreds of times larger
- Uses pure reinforcement learning without traditional training methods
- Excels at instruction following, knowledge QA, and math reasoning
- Processes twice as fast as competitors while using minimal memory
- Fully open source and optimized for edge device deployment