Inception Labs shakes up AI with Mercury2 - a diffusion model that thinks like an editor
A New Approach to AI Language Models
Artificial intelligence startup Inception Labs has taken a bold step away from industry norms with its newly released Mercury2 model. What makes this system special isn't just its performance - it's how fundamentally different its underlying technology works compared to most language models we use today.

Thinking Differently About Text Generation
While nearly all major language models rely on Transformer architecture (the technology behind ChatGPT and similar systems), Mercury2 takes inspiration from diffusion models - the same approach that powers many image generation tools. This isn't just swapping one technical solution for another; it changes how the AI processes information.
Imagine traditional AI writing like someone typing letter by letter on a keyboard. Mercury2 works more like an experienced editor reviewing an entire manuscript at once. Instead of generating text sequentially, it can evaluate and optimize multiple sections simultaneously.
"This parallel processing gives Mercury2 significant advantages," explains Dr. Elena Torres, Chief Scientist at Inception Labs. "When handling complex reasoning tasks or long documents, our model maintains context across the entire text rather than getting stuck in linear progression."
Speed That Turns Heads
The performance numbers tell an impressive story:
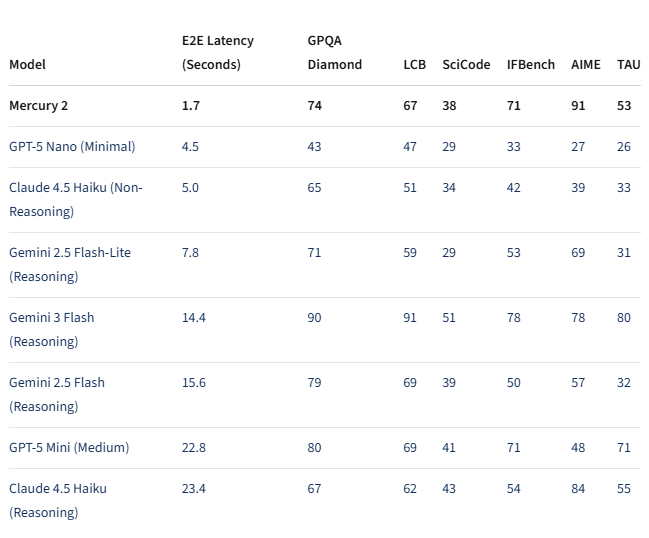
- Generates 1,009 tokens per second on NVIDIA Blackwell GPUs
- Responds in just 1.7 seconds end-to-end latency
- Outpaces competitors like Google's Gemini3Flash (8x faster) and Anthropic's Claude Haiku4.5
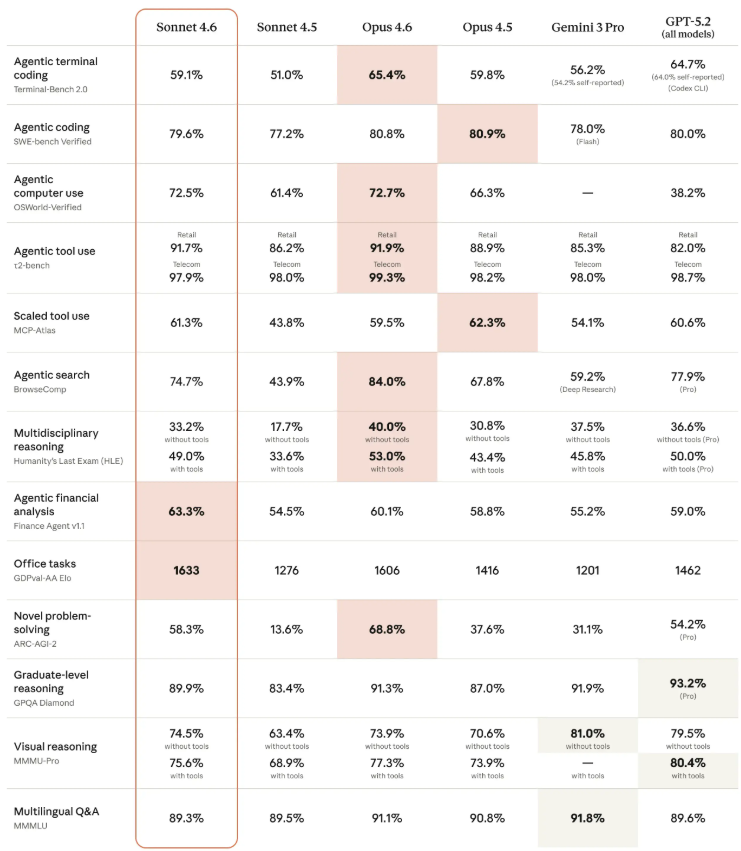
The speed doesn't come at the cost of quality either. In benchmark tests including GPQA Diamond and AIME (standard measures for reasoning ability), Mercury2 holds its own against today's top lightweight models.
Built For Business Needs
Inception Labs clearly designed Mercury2 with practical applications in mind:
- Cost-effective: Pricing comes in at about 25% of comparable services
- Enterprise-ready: Supports 128,000 token contexts and tool calling functions
- Specialized: Particularly suited for voice assistants, search systems, and coding tools where response time is critical
The API is already available for developers to test drive these capabilities firsthand.
Key Points:
- 🌀 Architecture revolution: Swaps Transformers for diffusion models enabling parallel text optimization
- ⚡ Blazing speed: Processes over 1K tokens/second with sub-2-second response times
- 💰 Budget-friendly: Disruptive pricing at quarter the cost of competitors