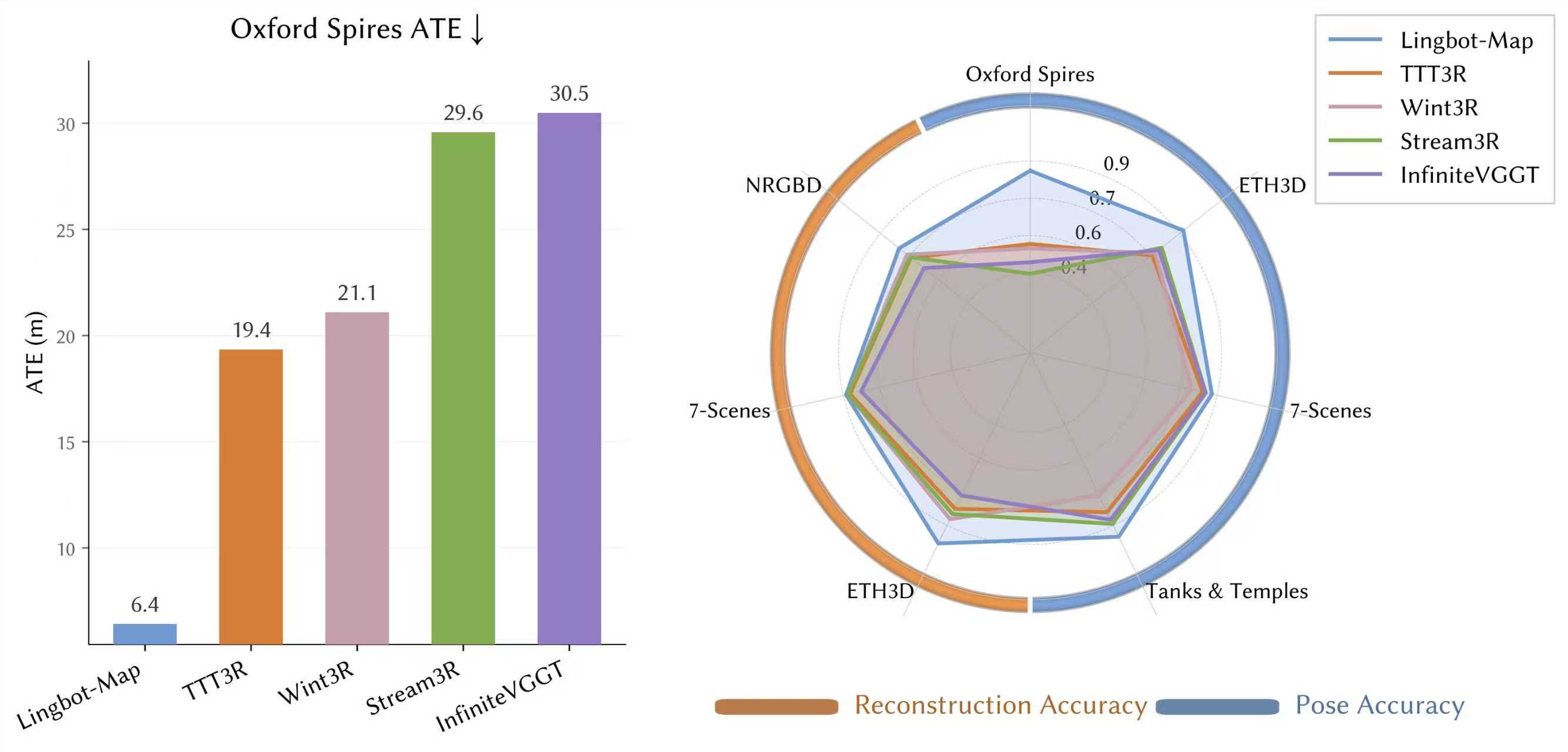
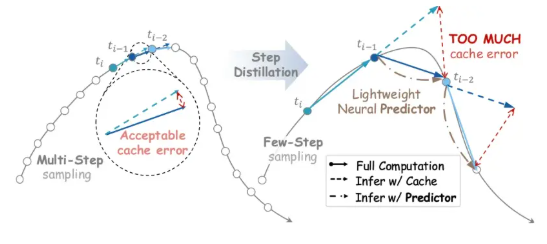
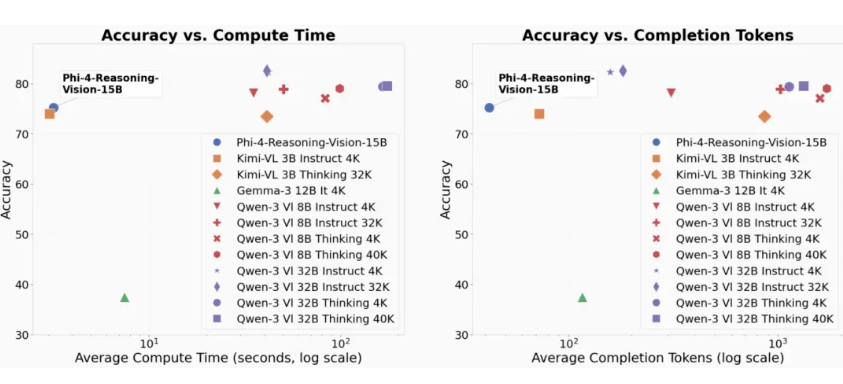
NVIDIA's Lyra 2.0 Turns Single Images into Expansive 3D Worlds
NVIDIA's Leap in 3D World Generation
Imagine feeding a single photograph into a system and getting back an entire explorable 3D universe. That's exactly what NVIDIA's new Lyra 2.0 framework accomplishes, marking a significant advancement in AI-powered spatial computing. Released on Hugging Face, this technology solves two persistent problems that have plagued digital world-building: spatial memory lapses and temporal distortions in generated content.

Solving the Memory Problem in Virtual Worlds
Traditional AI models tend to "forget" details of previously generated areas - a phenomenon researchers call "spatial forgetting." They also suffer from "temporal drift," where objects gradually shift position or appearance over time. These issues make creating consistent, large-scale environments challenging.
Lyra 2.0 tackles these problems with two innovative approaches:
- Spatial Memory Mechanism: Instead of storing every detail, the system maintains just enough 3D geometric information to establish connections between frames while relying on generative AI for the actual visual output. This prevents error accumulation that typically degrades quality over time.
- Self-Correcting Training: The model learns from its own mistakes during training, developing the ability to identify and correct drift rather than propagating it further.
From Snapshot to Virtual Playground
The process is surprisingly straightforward:
- Start with any image (text prompts optional)
- Plot a camera path through an interactive browser
- Watch as Lyra generates a video sequence following your path
- The system converts this into a 3D model (point cloud, Gaussian splatting, or mesh)
- Export directly to platforms like Unity or Unreal Engine
Early tests show Lyra outperforming existing methods in scene scale and consistency, creating environments spanning tens of meters that maintain stability even when revisiting areas. The potential applications are staggering - from training robots in virtual simulations to rapidly prototyping game worlds.
Open Access for Innovation
NVIDIA has made Lyra 2.0 freely available on Hugging Face (nvidia/Lyra-2.0) and GitHub (nv-tlabs/lyra) under the Apache 2.0 license. The system combines powerful diffusion models like Wan-14B with reconstruction tools such as Depth Anything V3 to ensure professional-grade output.
Key applications include:
- Creating realistic training environments for embodied AI and robotics
- Accelerating game development and immersive content creation
- Streamlining 3D asset pipelines from concept to finished product
The Future of Virtual Spaces
This release represents more than just technical achievement - it demonstrates how open ecosystems can drive industry-wide progress. As tools like Lyra become more accessible, we're likely to see an explosion of creative applications in fields ranging from autonomous vehicle testing to metaverse development.
For developers eager to experiment, the project page, research paper, and model weights are all publicly available. The era of easily accessible, AI-generated 3D worlds may have just begun.
Key Points:
- Lyra 2.0 generates persistent, consistent 3D environments from single images
- Solves "spatial forgetting" and "temporal drift" problems in AI generation
- Creates large-scale environments (tens of meters) suitable for navigation
- Open-source framework available on Hugging Face and GitHub
- Potential applications in gaming, robotics, and virtual world development