Meituan's New AI Model Packs Big Performance in Small Package
Meituan's Compact AI Model Delivers Outsized Performance

In the world of AI models, bigger hasn't always meant better. Traditional Mixture of Experts (MoE) architectures often hit diminishing returns as they scale up expert counts. Meituan's LongCat team flipped this script with their new LongCat-Flash-Lite model, achieving remarkable results through an innovative approach they call "Embedding Expansion."
Rethinking How Models Scale
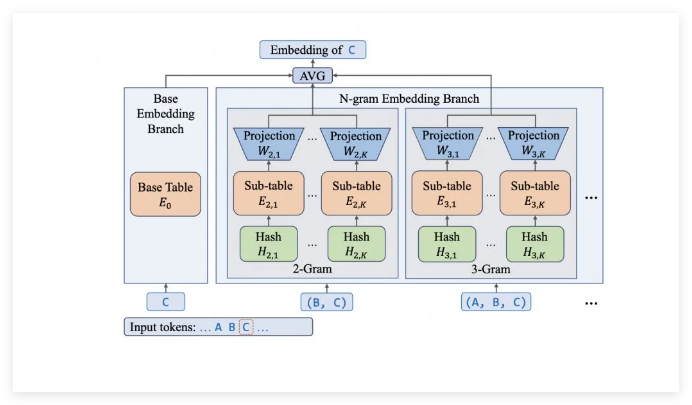
The breakthrough came when researchers discovered something counterintuitive: expanding embedding layers could outperform simply adding more experts. The numbers tell the story - while the full model contains 68.5 billion parameters, each inference activates just 2.9 to 4.5 billion parameters thanks to clever N-gram embedding layers.
"We've allocated over 30 billion parameters specifically to embedding," explains the technical report. "This lets us capture local semantics precisely - crucial for recognizing specialized contexts like programming commands."
Engineering Efficiency at Every Level
Theoretical advantages don't always translate to real-world performance. Meituan addressed this through three key optimizations:
- Smart Parameter Use: Nearly half (46%) of parameters go to embedding layers, keeping computational growth manageable.
- Custom Hardware Tricks: Specialized caching (similar to KV Cache) and fused CUDA kernels slash I/O delays.
- Predictive Processing: A three-step speculative decoding approach expands batch sizes efficiently.
The result? Blazing speeds of 500-700 tokens per second handling substantial inputs (4K tokens) with outputs up to 1K tokens - all supporting contexts as long as 256K tokens.
Benchmark-Busting Performance
The proof comes in testing where LongCat-Flash-Lite punches above its weight:
- Excels at practical applications like telecom support and retail scenarios on τ²-Bench
- Shows particular strength in coding (54.4% on SWE-Bench) and command execution (33.75 on TerminalBench)
- Holds its own generally (85.52 MMLU score) against larger models like Gemini2.5Flash-Lite
The entire package - weights, technical documentation, and SGLang-FluentLLM inference engine - is now open source through Meituan's LongCat API Open Platform, offering developers generous daily testing allowances.