Meituan's LongCat-Flash-Lite: A Lean AI That Packs a Punch
Meituan Rewrites the Rules of Efficient AI

In an industry obsessed with ever-larger models, Meituan's LongCat team has taken a different path. Their newly released LongCat-Flash-Lite proves that smarter architecture can outperform brute-force scaling. "We kept hitting diminishing returns with traditional MoE approaches," explains the team's technical lead. "Then we asked - what if we invested those parameters differently?"
The Embedding Layer Breakthrough
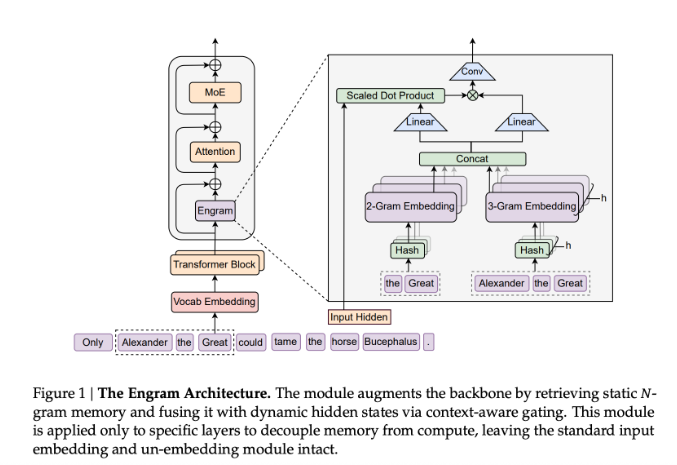
The secret sauce? A technique they call "Embedding Expansion." While most mixture-of-experts models keep adding specialists (think: hiring more consultants), LongCat-Flash-Lite supercharges its vocabulary understanding instead (like giving existing consultants better reference manuals).
Here's why it works:
- 68.5 billion parameters total, but only 2.9-4.5 billion activate per query
- Over 30 billion parameters dedicated to N-gram embeddings that grasp technical jargon effortlessly
- Specialized understanding for domains like programming commands (try confusing it with obscure terminal inputs)
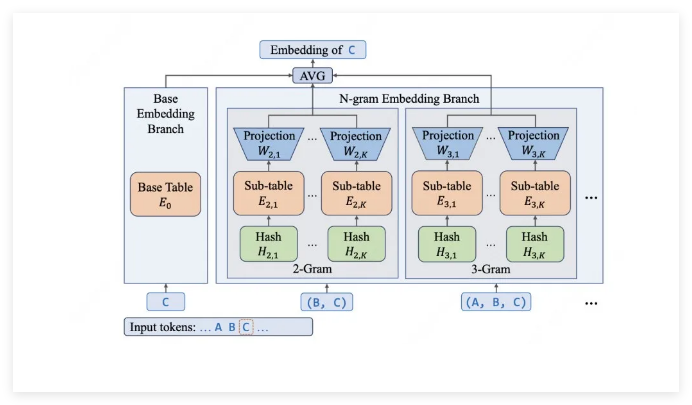
Engineering Magic Behind the Speed
Theoretical efficiency means nothing without real-world performance. Meituan's engineers delivered three clever optimizations:
- Parameter Diet Plan: Nearly half the model lives in lightweight embedding lookups (O(1) complexity - computer science speak for "blazing fast")
- Memory Tricks: A custom N-gram Cache system plus fused CUDA kernels cut down on computational paperwork
- Guessing Game: Speculative decoding lets the model anticipate likely outputs, like a chess player thinking several moves ahead
The payoff? Try 500-700 tokens per second - fast enough to generate Shakespeare's Hamlet in about 90 seconds while handling contexts up to 256K tokens.
Benchmark Dominance Across Fields
The numbers don't lie:
- Code Whisperer: Scores 54.4% on SWE-Bench (software engineering tasks) and dominates terminal command tests
- Mathlete: Holds its own against Gemini2.5Flash-Lite on MMLU (85.52) and competition-level math problems
- Specialist Agent: Tops charts for telecom, retail, and aviation scenarios on τ²-Benchmark
The kicker? Meituan has open-sourced everything - weights, technical papers, even their optimized inference engine. Developers can apply today via the LongCat API Open Platform with a generous 50 million token daily free tier. Because sometimes, the best things in AI don't come in the biggest packages.