DeepSeek's Memory Boost: How AI Models Are Getting Smarter
DeepSeek's Breakthrough Makes AI Models More Efficient
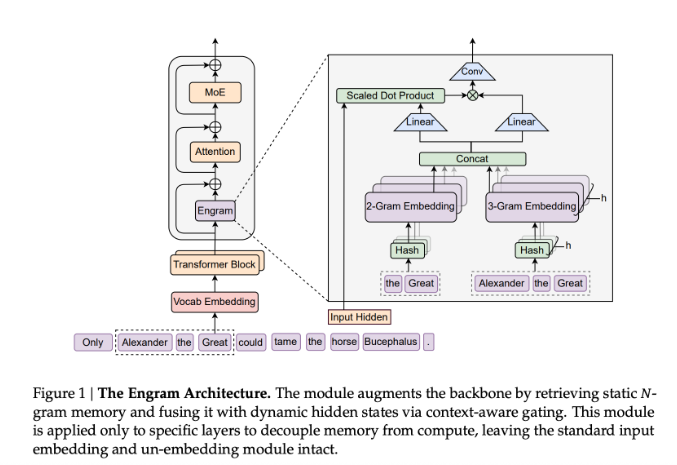
Imagine your brain having to relearn basic multiplication every time you did math. That's essentially what today's AI models endure when processing information. DeepSeek's research team has tackled this inefficiency head-on with their innovative Engram module - a sort of cheat sheet that helps artificial intelligence work smarter, not harder.
How Engram Changes the Game
The breakthrough comes from recognizing how current Transformer models waste energy. "These systems keep solving the same simple problems over and over," explains the research paper. Engram solves this by creating quick-access memory slots for frequently used information like common phrases and names.
Unlike previous approaches that tried replacing core systems, Engram works alongside existing technology. Think of it as adding sticky notes to a textbook rather than rewriting chapters. This elegant solution maintains stability while boosting performance.
Real-World Results That Impress
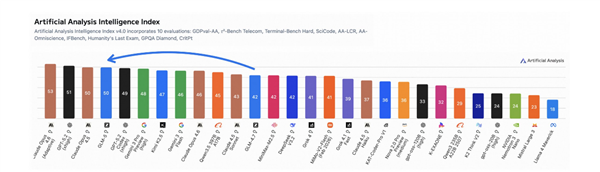
The numbers speak volumes:
- Testing on 262 billion data tokens showed significant improvements
- Models allocated just 20-25% of resources to Engram saw noticeable gains The Engram-27B and Engram-40B models consistently outperformed standard versions across multiple benchmarks including:
- General knowledge (MMLU)
- Math problems (GSM8K)
- Coding challenges
Perhaps most exciting is Engram's ability to handle lengthy documents. When stretched to process 32,768-word contexts - roughly equivalent to a short novel - these enhanced models maintained impressive accuracy in finding specific details.
Why This Matters Beyond Benchmarks
The implications extend far beyond test scores:
- Energy Efficiency: Less computational waste means greener AI operations
- Scalability: The system grows gracefully with model size
- Practical Applications: From legal document review to medical research, longer context understanding unlocks new possibilities
- Future Development: This approach suggests new pathways for AI architecture improvements
The DeepSeek team emphasizes they're just scratching the surface of what conditional memory axes can achieve.
Key Points:
- Smarter Architecture: Engram's O(1) hash lookup gives instant access to common knowledge
- Measurable Gains: Both 27B and 40B models showed clear advantages over traditional designs
- Long Text Mastery: Enhanced recall abilities shine with extensive documents
- Resource Friendly: Does more with less by eliminating redundant calculations