Character.AI Launches AI-Native Social Feed
Character.AI Redefines Social Media with AI-Native Community Feed
Character.AI has launched its Community Feed feature, marking a significant shift in social media interaction. This innovation positions the platform as the world's first AI-native social network, blending artificial intelligence with user creativity through multimodal tools.
From Passive Scrolling to Active Co-Creation
The Community Feed fundamentally changes how users engage with content. Rather than passively consuming posts, participants can:
- Interact directly with AI characters
- Modify existing storylines
- Initiate new narrative branches
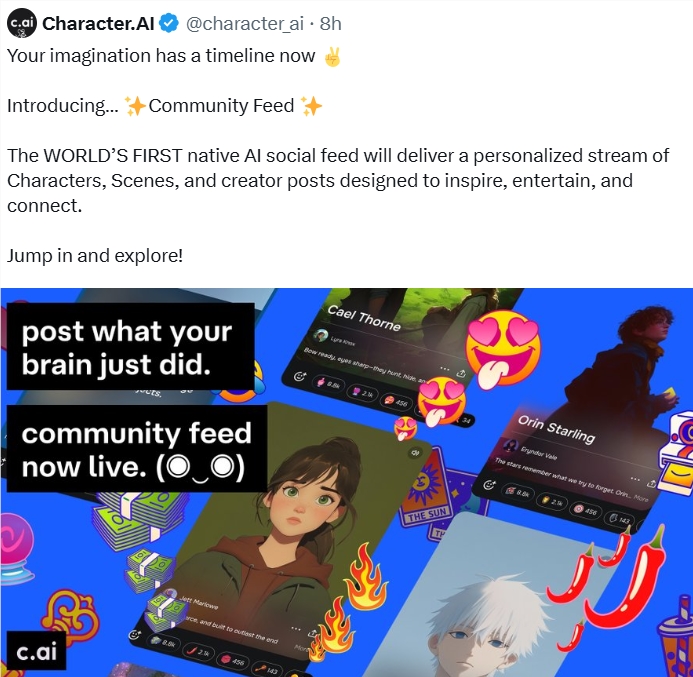
"We're erasing the distinction between creators and audiences," explained CEO Karandeep Anand. "Every user can either enjoy content or actively shape it into personalized adventures."
Multimodal Toolkit Powers Creativity
The platform provides specialized tools to facilitate diverse content creation:
| Feature | Functionality |
|---|
These tools enable professional-quality output without requiring technical expertise from users.
Safety and Moderation Systems
While encouraging creative freedom, Character.AI implements robust safeguards:
- Automated content classifiers for text and video
- 24/7 monitoring by Trust & Safety teams
- User-controlled content filters and reporting options The company acknowledges past controversies and emphasizes ongoing improvements to balance innovation with community protection.
Competitive Landscape in AI Social Space
The feature debuted on web platforms in June 2025 before expanding to mobile. Character.AI faces growing competition from:
- Pika's experimental video features
- Meta's AI integration projects
- OpenAI's social content initiatives
The company maintains an edge through its native AI architecture, designed specifically for intelligent interaction rather than retrofitting AI onto existing platforms.
Industry Implications
This development signals a potential paradigm shift in social media:
- Transition from algorithmic feeds to collaborative creation
- New metrics for measuring user engagement
- Emerging standards for AI-human content partnerships
- Evolution of digital identity through persistent AI characters
- Technical challenges in maintaining real-time multimodal generation
The advancement reflects growing maturity in natural language processing, video synthesis, and interactive narrative systems.
Key Points:
- First true AI-native social platform launches interactive feed
- Multimodal tools enable co-creation with AI characters
- Advanced safety measures accompany creative features
- Early market lead against tech giants' competing projects
- Potential to redefine social media engagement metrics