Ant Group's Latest AI Model Raises the Bar for Multimodal Tech
Ant Group's Open-Source Breakthrough Pushes Multimodal AI Forward
In a significant move for the AI community, Ant Group released Ming-Flash-Omni 2.0 as open-source software on February 11. This advanced multimodal model isn't just another incremental update—it's setting new benchmarks that challenge even Google's Gemini 2.5 Pro in certain performance metrics.
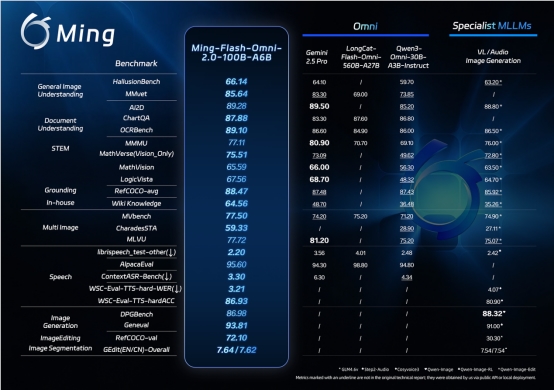 (Caption: Ming-Flash-Omni-2.0 demonstrates leading capabilities in visual language processing and multimedia generation.)
(Caption: Ming-Flash-Omni-2.0 demonstrates leading capabilities in visual language processing and multimedia generation.)
Hearing the Difference
What makes this release particularly noteworthy is its audio capabilities. Imagine giving natural language instructions like "make the voice sound excited with a southern accent" or "add rain sounds underneath the piano melody"—that's precisely what developers can now achieve. The model handles these complex audio tasks with remarkable efficiency, generating minute-long high-fidelity audio at just 3.1Hz frame rates.
Seeing More Clearly
The visual improvements are equally impressive. The team fed billions of fine-grained examples into the system, resulting in exceptional performance on tricky recognition tasks—whether distinguishing between similar dog breeds or identifying intricate craftsmanship details in cultural artifacts.
Zhou Jun, leading Ant Group's Bai Ling model team, explains their philosophy: "True multimodal technology shouldn't feel like separate tools bolted together. We've built a unified architecture where vision, speech, and generation capabilities naturally enhance each other."
Practical Benefits for Developers
For those building AI applications:
- Simplified workflow: No more stitching together specialized models
- Cost reduction: Single-model efficiency lowers computational expenses
- Creative possibilities: New frontiers in multimedia content generation
The model weights and inference code are now available on Hugging Face and through Ant's Ling Studio platform.
What's Next?
The team isn't resting on their laurels. Future updates will focus on:
- Enhanced video timeline understanding
- More sophisticated image editing tools
- Improved real-time long-form audio generation
The release signals an important shift toward more integrated multimodal systems—ones that might finally deliver on the promise of AI that understands our world as holistically as humans do.
Key Points:
- Industry-leading performance in multiple benchmark tests
- First unified audio model handling speech, effects, and music simultaneously
- Natural language control over voice parameters like emotion and dialect
- Open-source availability lowers barriers for developers worldwide