大型语言模型的算术挑战
大型语言模型的算术挑战
大型语言模型(LLMs)在执行多种任务方面取得了显著进展,包括写诗、编程和参与对话。然而,尽管它们的能力令人印象深刻,这些AI系统通常在基本算术方面存在困难,导致得出结论:它们本质上是‘数学新手’。最近的一项研究揭示了这一现象的根本原因,显示它们的算术推理严重依赖一种被称为 ‘启发式拼凑’的策略。
启发式拼凑策略
根据研究,LLMs并不使用复杂的算法或仅依靠存储的信息;相反,它们采用一种类似于没有透彻学习数学原理的学生的方法。这种方法涉及根据混合的学习规则和模式进行有根据的猜测,而不是遵循系统的方法。
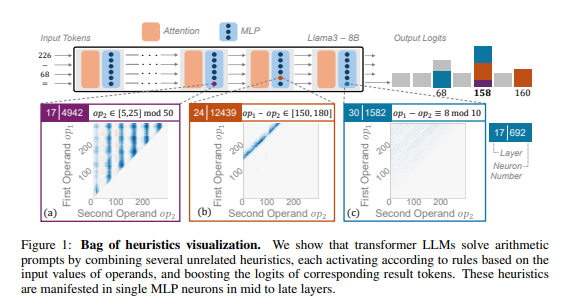
研究人员对几种突出的LLMs进行了深入分析,包括Llama3、Pythia和GPT-J,专注于它们的 算术推理 能力。根据发现,负责算术计算的神经结构由许多独立的神经元组成。每个神经元充当一个 ‘迷你计算器’,负责识别特定的数字模式并生成相应的输出。例如,一个神经元可能专注于识别以8结尾的数字,而另一个则可能专注于产生结果在150到180之间的运算。
工具的随机组合
这些 ‘迷你计算器’ 的运作方式是无序的,因为LLMs并没有通过定义的算法来使用它们。相反,它们根据接收到的输入随机组合这些神经工具,导致结果各异。这个过程可以类比为一个厨师在没有固定食谱的情况下即兴创作一道菜,依赖于手头的任何材料。
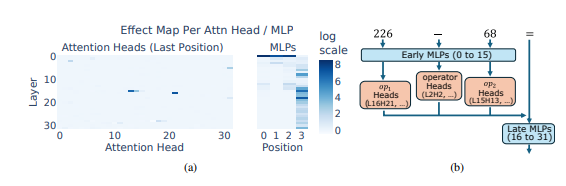
有趣的是,研究发现这种 启发式拼凑 策略并不是LLM训练中的新发展。相反,它早在训练初期就已经出现,并随着模型的继续学习而得到完善。这表明LLMs在训练的早期阶段就依赖于这种有些混乱的推理方法,而不是后来才发展的。
局限性和影响
这种 古怪的 算术推理方法的影响是显著的。研究人员指出,启发式拼凑 策略的推广能力有限,容易出错。模型的聪明才智有限,意味着它可能在面对新颖的数字模式时表现不佳,就像一个只会做 ‘西红柿炒鸡蛋’ 的厨师在制作 ‘鱼味 shredded pork’ 时会遇到困难一样。
这项研究揭示了LLMs算术推理固有的局限性,并建议未来在其数学技能方面的改进途径。作者主张,仅依靠现有的培训技术和模型架构可能不足以增强LLMs的算术能力。相反,必须探索创新策略,以促进更强大和更通用算法的发展,最终使LLMs在数学方面变得更加熟练。
有关更多详细信息,完整研究论文可在 这里 访问。
要点
- 大型语言模型在基本算术方面挣扎,通常依赖于‘启发式拼凑’策略。
- 这种方法结合了各种学习的模式,而不是利用系统性的推理。
- 该策略的局限性突显了改进LLMs数学能力的新培训方法的必要性。