Voice Editing Just Got Easier: Meet the AI That Edits Speech Like Text
Voice Editing Revolution: AI Makes Speech Modification as Easy as Typing
Imagine tweaking someone's tone of voice as easily as you edit a text message. That's the promise of StepFun AI's new Step-Audio-EditX, an open-source project that's set to transform how we work with audio.
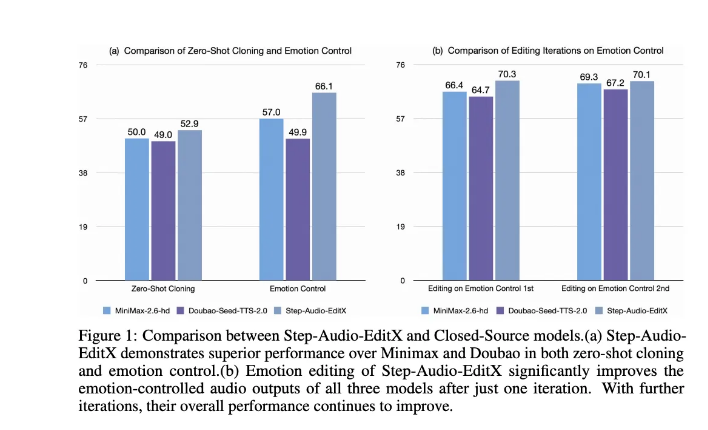
Beyond Voice Cloning: Precise Control Arrives
While current voice systems can mimic emotions and accents from samples, they often struggle with specific instructions. Step-Audio-EditX changes the game by treating speech modification like text editing - allowing developers to adjust emotions, styles, and even subtle vocal cues through simple commands.
The secret? A novel approach that trains on speech samples with identical words but different vocal qualities. "We're teaching the system what 'angry' or 'excited' sounds like," explains the team behind the technology, "so it can apply those qualities on demand."
How It Works: Dual Codebooks Meet Massive Training
The system builds on StepFun's earlier audio work with:
- Two specialized tokenizers capturing language (16.7Hz) and semantic (25Hz) information
- A compact 3B parameter model trained equally on text and audio data
- Advanced reconstruction using diffusion transformers and BigVGANv2 vocoder
What makes this different? Traditional systems might modify waveforms directly - think of it like painting over an existing recording. Step-Audio-EditX works more like word processing, letting you "select" vocal qualities and "paste" them elsewhere.
Training Tricks That Make It Work
The team employed several innovative techniques:
- Large Margin Learning: Training on speech triplets showing dramatic differences in delivery while saying the same words
- Massive Data Collection: 60,000 speakers across multiple languages/dialects, plus professional voice actor recordings
- Two-Stage Refinement: Initial supervised learning followed by reinforcement training for natural responses
The results speak for themselves - accuracy jumps of 20-27% in emotional/style control compared to previous methods.
Why This Matters Beyond Tech Circles
The implications extend far beyond developer tools:
- Podcasters could tweak delivery after recording without re-speaking lines
- Audiobook narrators might adjust pacing or tone across an entire chapter
- Language learners could hear proper pronunciation variations instantly And because it's fully open-source (including model weights), innovation could accelerate rapidly.
The team sees this as just the beginning: "We're entering an era where voice isn't just recorded - it's designed."
Key Points:
- First system enabling text-like editing of vocal qualities
- Open-source model handles emotion, style and paralinguistic features
- Significant accuracy improvements over existing methods
- Potential applications across media production and accessibility