VideoFrom3D Transforms Rough Geometry into Realistic 3D Videos
VideoFrom3D Transforms Rough Geometry into Realistic 3D Videos
In the rapidly evolving world of AI-driven creativity, VideoFrom3D emerges as a game-changer for 3D graphics design. This innovative framework leverages diffusion models to generate highly realistic and stylistically consistent 3D scene videos from minimal inputs—rough geometries, camera paths, and reference images. By eliminating the need for costly paired datasets, VideoFrom3D democratizes high-quality 3D content creation.
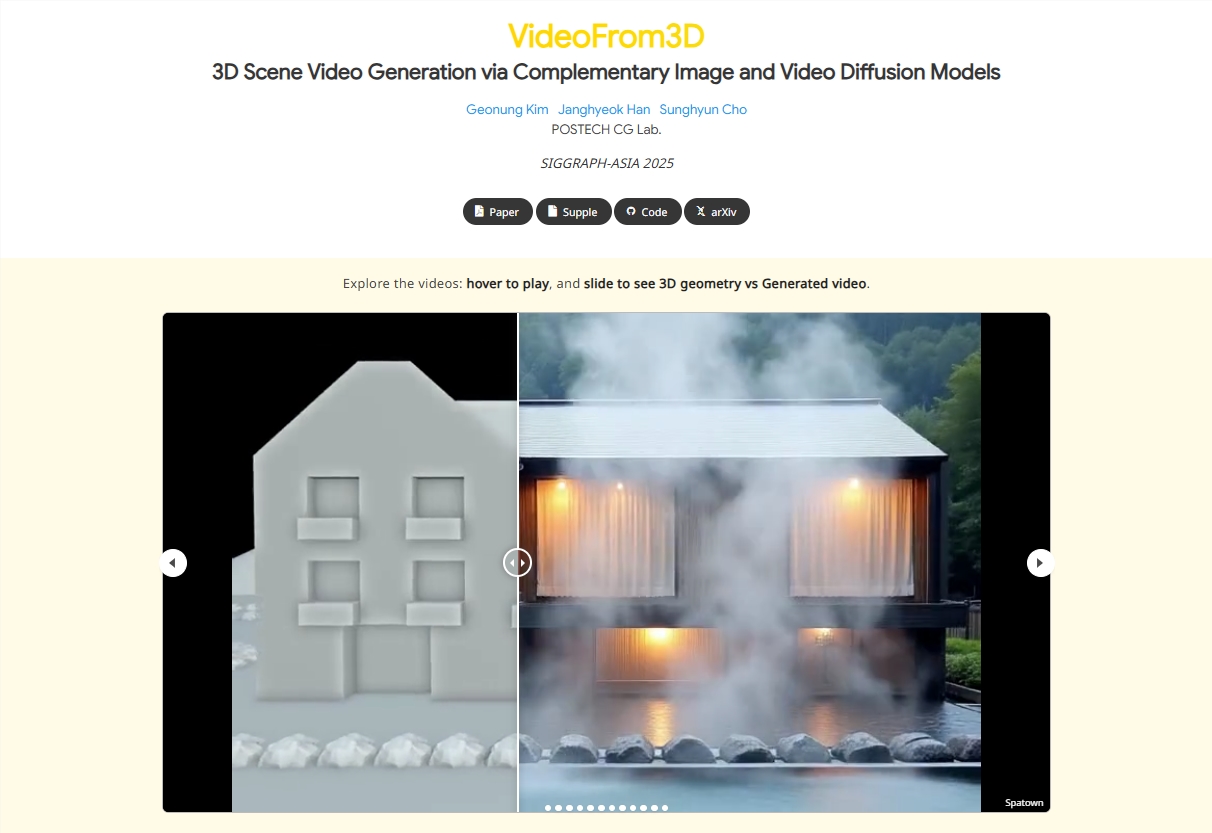
Framework Core: Dual-Module Architecture
The power of VideoFrom3D lies in its dual-module architecture:
- Sparse Anchor View Generation (SAG) Module: Uses an image diffusion model to produce high-quality, cross-view consistent anchor views based on reference images and rough geometry.
- Geometry-Guided Generative Interpolation (GGI) Module: Leverages a video diffusion model to interpolate intermediate frames, ensuring smooth motion and temporal consistency through flow-based camera control.
This approach sidesteps traditional challenges like visual quality degradation and motion inconsistencies in complex scenes.
Technical Highlights: Zero-Paired Data Strategy
Unlike conventional methods reliant on annotated datasets, VideoFrom3D adopts a "zero-paired" strategy, requiring only:
- Rough geometry (e.g., simple meshes or point clouds)
- A camera path
- A reference image
This innovation lowers barriers for designers and supports diverse applications—from indoor scenes to outdoor landscapes—while maintaining style consistency across views.
Performance and Applications
Benchmark tests reveal that VideoFrom3D outperforms existing models, particularly in dynamic scenes. Its outputs rival professional-grade productions with natural motion and stylistic fidelity.
The framework has far-reaching implications:
- Film & Special Effects: Accelerates pre-visualization and prototyping.
- Virtual Reality: Enables rapid scene construction for immersive experiences.
- Game Development: Streamlines asset creation for indie developers. By reducing reliance on expensive datasets, it empowers small teams to compete with industry giants.
Key Points:
- Innovation: Combines image and video diffusion models for seamless 3D video generation.
- Accessibility: Eliminates need for paired datasets, lowering production costs.
- Quality: Delivers professional-grade outputs with consistent styling and motion.
- Versatility: Applicable across industries from gaming to architectural visualization.