mmBERT Outperforms XLM-R in Multilingual NLP Efficiency
Breakthrough in Multilingual NLP: mmBERT Sets New Standards
A research team from Johns Hopkins University has introduced mmBERT, a revolutionary multilingual encoder that outperforms existing models like XLM-R in both speed and accuracy. This advancement addresses critical gaps in multilingual natural language processing (NLP), offering enhanced support for global language applications.
Architectural Advancements
The mmBERT framework features two primary configurations:
- Base model: 22 transformer layers, 1152 hidden layer dimension (~307M parameters)
- Small model: Optimized with ~140M parameters

Key technological innovations include:
- Gemma2 tokenizer supporting 256k vocabulary
- Rotary position embeddings (RoPE)
- FlashAttention2 technology
- Expanded sequence length from 1024 to 8192 tokens
Comprehensive Training Approach
The model was trained on an unprecedented dataset:
- 3 trillion tokens across 1833 languages
- English constitutes only 10%-34% of corpus
- Three-phase training strategy:
- Pre-training foundation
- Mid-training refinement
- Decay stage optimization

The phased approach ensures gradual exposure to diverse languages, particularly benefiting low-resource language performance.
Benchmark Dominance
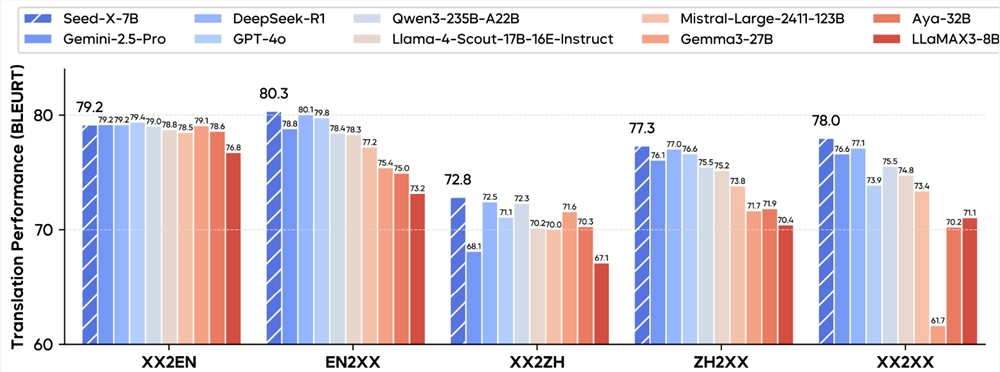
mmBERT demonstrates superior performance across multiple evaluations:
| Benchmark | mmBERT Score | XLM-R Score |
|---|
The model also excels in:
- Embedding tasks
- Code retrieval applications
- Low-resource language processing (Faroese, Tigrinya)
Future Implications
This breakthrough redefines possibilities for:
- Global communication systems
- Cross-language AI applications
- Preservation of linguistic diversity making mmBERT a cornerstone for next-generation multilingual NLP systems.
The open-source model is available at: GitHub Repository
Key Points:
✅ Performance Leader: Surpasses XLM-R across multiple benchmarks ⏱️ Speed Advantage: Processes data 2-4x faster than predecessors 🌐 Language Inclusion: Specialized training enhances low-resource language capabilities