Meituan Launches VitaBench for AI Agent Evaluation
Meituan's LongCat Team Introduces VitaBench: A New Standard for AI Agent Evaluation
Meituan's LongCat research team has unveiled VitaBench, a comprehensive benchmark designed to evaluate intelligent agents performing multi-interaction tasks in real-life scenarios. This new framework specifically targets high-frequency use cases including food delivery, restaurant dining, and travel arrangements.
Addressing Real-World AI Challenges
The development comes as current AI systems show significant limitations in complex scenarios. According to LongCat's research, even leading reasoning models achieve less than 30% success rates in cross-scenario tasks. VitaBench aims to bridge this gap between laboratory performance and practical application needs.
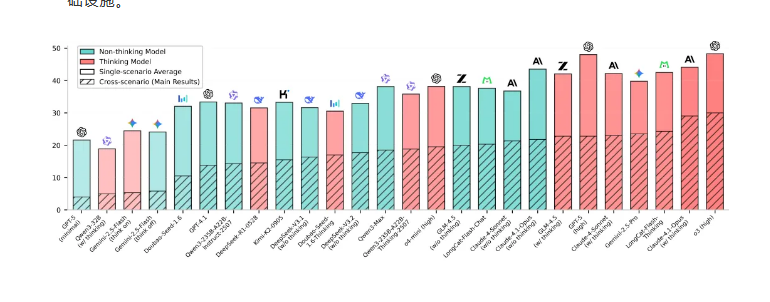
Comprehensive Evaluation Framework
VitaBench features:
- 66 interactive tools simulating real-world services
- Complex task simulations including ticket purchasing and restaurant reservations
- Three-dimensional evaluation criteria:
- Reasoning complexity: Measures information integration needs and observation space size
- Tool complexity: Evaluates dependency relationships and call chain length
- Interaction complexity: Assesses multi-turn dialogue capabilities
The benchmark's two-stage construction process ensures task diversity while avoiding the limitations of traditional document-based evaluation methods.

Open Source Availability
The team has made VitaBench fully accessible to the research community through:
- Official project homepage with documentation
- GitHub repository containing all code
- Hugging Face dataset hosting
- Public leaderboard tracking performance metrics
Key Points:
- VitaBench evaluates AI agents across three critical dimensions
- Current systems struggle with sub-30% success rates in complex tasks The framework focuses on real-world applicability beyond academic benchmarks The project is now fully open source for community adoption

